Table of Contents
- 1. Introduction
- 2. Before You Get Started
- 3. TMCore API Programming Kickstart
- 4. TMCore API Overview
- 5. Core API
- 6. Indexes
- 7. Importing and Exporting XTM Files
- 8. TMCore System Utilities
- 9. Querying
- 10. Fast Topic Map Updates with the TransactionalPersistenceManager
- 11. The NetworkedPlanet Constraint Language (NPCL)
- 12. The NPCL Constraints API
- 13. Duplicate Removal
- 14. Logging
List of Figures
List of Tables
- 5.1. ITopicMapSystem Configuration Properties
- 6.1. TMAPI Core Indexes
- 8.1. Topic PSIs for Topic Hierarchies
- 11.1. NPCL Meta Types
- 11.2. Occurrence Type Value Facets
- 11.3. NPCL Constraint Topic Types
- 11.4. Minimum And Maximum Cardinality Facet Meanings
- 11.5. Associations Required To Specify An Occurrence Constraint
- 11.6. Associations Used To Specify A Role Player Constraint
- 11.7. Associations Required To Specify An Association Role Constraint
- 12.1. Interfaces Representing the NPCL Model
- 12.2. NPCL API Examples
List of Examples
- 3.1. Creating a Topic Map
- 3.2. Topic Map Application Configuration File
- 3.3. Safely Creating a Topic Map
- 3.4. Creating and Populating Topics
- 3.5. Creating and Populating Associations
- 3.6. Looping over Topics and Associations
- 3.7. Accessing Topic Data
- 3.8. The Main Program Flow
- 3.9. Creating the Topic Map Ontology
- 3.10. Using Indexes
- 3.11. Listing All Topic Types
- 3.12. Reading An XTM File
- 3.13. Writing An XTM File
- 5.1. A simple .config file for a TMCore Application
- 7.1. Examples of Importing Into TMCore
- 9.1. Using ITMCoreDataReader
- 9.2. Using ExecuteQuery(string, IList)
- 9.3. Using ExecuteQuery(string, Hashtable)
- 11.1. XTM For A Topic Type
- 11.2. An Abstract Topic Type
- 11.3. Occurrence Type Value Facets In XTM
- 11.4. Topic Type Scoping Facets In XTM
- 11.5. The Arc Label Facet Expressed in XTM Syntax
- 11.6. Example Occurrence Constraint
- 11.7. A Role Player Constraint Specified In XTM
- 11.8. An Association Role Constraint in XTM
- 12.1. C# Code To Create An NPCL Schema
- 12.2. Writing a Schema as XML
- 12.3. Writing A Schema Into A Topic Map
- 12.4. Reading A Schema
- 12.5. Generating An NPCL Schema File From A Topic Map
- 12.6. Generating And Adding Schema Information To A Topic Map
Table of Contents
TMCore provides a complete Application Programming Interface (API) for accessing and manipulating topic map data. The implementation of this API provided by TMCore is written entirely in C# as managed code. This allows the API to be accessed from any programming lanuage supported by the Microsoft Common Language Runtime (CLR), including C#, J#, VB.NET and, with suitable extensions, Python and Perl.
The API provided by TMCore is based on the open API standard, TMAPI (see http://tmapi.org/ for more details) which has been specified in Java. The TMCore API differs in that it makes use of features of C# and VB such as object properties and also provides a number of extra convenience functions for developers. However the full range of capabilities of TMAPI are present in the TMCore API (and much more besides!)
This document provides a guide to the TMCore APIs for developers. The examples are provided in the distribution in both C# and VB. In this document, however we show only the C# notation.
This guide is NOT a method-by-method listing of
all of the interfaces of the TMCore API. For such a listing, for this, the
reader is directed to the HTML Help File
tmcore-api.chm which is part of the TMCore
distribution.
Portions of this document are based on the TMAPI Developer's Guide and Quickstart document produced by the TMAPI project team.
This document uses a number of typographical convetions to highlight particular types of words or sections of text.
Namespace, class and interface names are all displayed in a monospaced font. e.g
NetworkedPlanet.TMAPI,ITopic.Method names are displayed in a monospaced font. When referring to a particular overload of a method, the method parameters are displayed, otherwise they are omitted. The first time a method is referred to in the text, the method name is qualified by the interface or class that it is a member of e.g.
ITopic.CreateTopicName()File names are shown in bold monospaced font e.g.
App.config
In addition the following conventions are used to highlight sections of the text:
Note
This is a note. A note highlights or expands on something mentioned in the text.
Warning
This is a warning. A warning alerts you to a critical piece of information.
[1] // This is a program listing
[2] // It contains a code snippet which is relevant to the text
[3] // Lines may be numbered for references from the textThis is computer output
It shows the text output that results
from running a command-line application.
The following list shows the major changes to the API since TMCore05 SP1. Changes are listed as CRITICAL, NEW or UPDATED. A CRITICAL change is one which requires attention to any applications written with an older version of TMCore - this category includes all changes that might break an existing application when moving to the new version of the library. A NEW change is one which introduces new functionality to TMCore. An UPDATED change is one which modifies existing functionality without causing backwards compatibility issues.
This section lists the major changes introduced in TMCore07 Service Pack 3.
NEW: Added stored procedures for duplicate removal. Two new public stored procedures have been added to the database that identify and remove duplicate information from either a single topic map or from all topic maps in the database. Refer to the section called “Duplicate Removal Procedures” for more details.
NEW: A new API has been made available for performing fast transactional updates to a topic map. This new API allows developers to create and delete objects as well as modify existing objects. Because the API is implemented as direct database updates, a series of topic map updates written using the API is typically many times faster than the equivalent series of updates written using TMAPI. Refer to Chapter 10, Fast Topic Map Updates with the TransactionalPersistenceManager for more details.
UPDATED: The NPCL Forms Schema has been extended to return additional information useful in creating topic map editing interfaces. In particular the schema provides information about the database OIDs of the difference topic, association, role and occurrence types; the schema provides additional information about the cardinality constraints of each topic; and the forms schema now also properly reports all the role player types allowed in a role when the role player constraint omits the optional association type.
The updated schema is described in detail in the Web Services Guide document.
This section lists the the major changes introduced in TMCore07
NEW: The ITopicMapObject interface now exposes a new readonly property ID. This presents the object identifier as a 32-bit integer.
NEW: The ITopicMapSystem interface now exposes two overrides for the ExecuteQuery method. These overrides allow you to specify SQL parameters in a TMRQL query string and provide values for those parameters rather than relying on string concatenation. It is STRONGLY RECOMMENDED that you use these overrides in preference to the original ExceuteQuery(String) method. Refer to the section called “Executing Queries” for more details.
NEW: A new assembly NetworkedPlanet.Npcl provides APIs for creating and reading topic map schema information using the Networked Planet Constraint Language (NPCL). Refer to Chapter 12, The NPCL Constraints API for more information about these APIs.
NEW: A new web service application, npclws implements the NPCL Schema Web Service. This provides access to retrieve an XML representation of the NPCL schema governing a topic map or a single topic type within a topic map. Refer to the Web Service Guide for more information. The operations of this web service can be accessed via SOAP or using HTTP GET or POST requests.
NEW: New views have been added to the database to allow querying of the NPCL schema information in a topic map using TMRQL. See the TMCore Query Reference Sheet for an overview of these new views. The new veiws can be easily identified as their names all start with the prefix "tm_npcl".
UPDATED: The serviceclient.dll assembly that in previous versions contained only the SOAP web service stubs for the Topic Map Web Service now also contains the SOAP web service stubs for the NPCL Schema Web Service and classes for representing the structure of input and output XML used by the web services.
NEW: A new database user-defined function, tm_tc3 has been added. This function performs a transitive closure starting from a specified topic and using a set of association types and role types to determine the paths traversed.
UPDATED: The Topic Map Web Service now implements a new operation named ProcessTransaction. This operation allows a set of updates to a topic map to be described as a simple XML document and passed to the web service for processing as a single update transaction. This operation is, in most cases, far more efficient at updating specific topics and associations than the previously supported Save operation. However, the Save operation remains part of the Topic Map Web Service interface to enable efficient creation of new topics and associations in a topic map. For more details about this operation, please refer to the Web Services Guide.
NEW: The Topic Map Web Service now provides an ASP.NET-based implementation of the service allowing access to the operations using HTTP GET or HTTP POST requests. Unlike the SOAP HTTP transport, these interfaces implement all of the operations of the Topic Map Web Service.
CRITICAL : The namespace NetworkedPlanet.TMAPI.Utils is now deprecated. All utility classes can be found in the namespace NetworkedPlanet.TMCore.Utils. The HierarchyManager class which was found in NetworkedPlanet.TMAPI.Utils has been moved, although an implementation remains under the old namespace for this release only to aid in any transition.
NEW: The class NetworkedPlanet.TMCore.Utils.ApplicationOntology provides utilities for managing cached references to topics that can be particularly useful in creating more readable and more efficient TMRQL queries. For more details please refer to the section called “The ApplicationOntology Object”.
NEW: Two new methods are added to the interface NetworkedPlanet.TMAPI.Query.ITMCoreDataReader. The method ITMCoreDataReader.GetInternalDataReader() returns the underlying IDataReader instance wrapped by the ITMCoreDataReader instance. The method ITMCoreDataReader.GetDataTable() reads from the data reader and returns DataTable instance containing the full results set. For more details please refer to the section called “Executing Queries”.
NEW: The public methods ITopic.Reload() and IAssociation.Reload() have been added to allow the local copy of a topic or association to be updated from the database, overwriting any local modifications.
NEW: A new public user-defined function in the database, tm_tc2 can be used to compute a transitive closure returning a list of {start, end} pairs that can hugely improve the time taken to process a hierarchy of topics. For more details, please refer to the separate Query Reference Sheet.
This document contains sample code that you can compile and run against your own installation of TMCore. Of course, in order to do that there are certain prerequisites. The main prerequisite is that you are able to connect to a SQLServer database that has been configured with the TMCore schemas. Either you or your systems administrator can set up such a database by following the instructions contained in the TMCore Installation Guide. Once the database is set up, you will need the following information:
The hostname or IP address of the SQLServer that hosts the TMCore database you are using for your testing.
The name of the TMCore database you are using for your testing.
The type of authentication required to connect to the database and any user name and password information. A SQLServer database supports Windows-based authentication (which makes use of your Windows logon to determine if you are allowed to access the database) and can also support database-specific user name and password. Your systems administrator will be able to tell you which is configured for your database. If you are connecting using your Windows logon, you need to make sure that you have been granted the necessary access privileges. These are detailed in the TMCore Installation Guide. If you are connecting using a database-specific user name and password, you will need that information.
Table of Contents
This chapter presents some easy examples of how to start working with the TMCore API. The following examples are a little bit more than the typical "Hello World" application you find at the start of programming texts. Our first example provides code for creating a topic map from scratch using the TMCore APIs. The second example is a bit more complex, it generates a topic map that represents the directories and files contained in a given directory on the file-system. This second example shows more use of the APIs for creating and modifying topic map data and also shows the use of the indexing system provided by the API. The third example shows how to write a topic map out to an XTM file and the final example shows how to import topic map data from an XTM into the TMCore system.
The full source code for these examples can be found in the
examples/ directory of the TMCore distribution. The
directory contains both C# and VB.NET versions of the examples in the
subdirectories CS and VB respectively. Each example is provided in a
separate directory with its own project file. To compile and run an
example, open Visual Studio.NET and create a new blank solution; then
add the .csproj or .vbproj for the example to the solution. The project
can then be built using the Build > Build Solution menu item. If the
solution contains multiple projects, set the new example project to be
the start-up project by right clicking the project in the Solution
Explorer pane and selecting "Set as StartUp Project" from the pop-up
menu.
Some of the examples allow command line parameters to be specified. From within Visual Studio, you can assign the command line parameters to be used when running an example by bringing up the Properties pane for the project (right click on the project in the Solution Explorer and select "Properties"). In the Properties Pane select the item "Debugging" under "Configuration Properties" and in the field labelled "Command line arguments", enter the parameters. However, all of the example programs are written so that they can be run from within Visual Studio without specifying any command line parameters.
Finally, to run the project, press F5 or choose the Debug > Start menu item.
Note
You may find that the project files contain an invalid reference to the TMCore assembly. You can check this by opening the "References" icon under the project name in the solution explorer of Visual studio. If you see the reference named "tmcore" with a yellow warning triangle next to it, then the reference is invalid and must be changed before you can successfully compile the project. To change the reference, delete the existing reference and then right click on the "References" icon and select . In the dialog that is displayed, click and browse to the tmcore.dll that came with the TMCore installation. Finally, click the button to dismiss the dialog. You should now see the tmcore reference appear under "References" with no warning triangle next to it.
This section contains a little example of how to create a topic
map including two topics and an association. This example also prints
the content of the topic map. This example can be found in the directory
examples/CS/APIExample1 or
examples/VB/APIExample1.
Example 3.1. Creating a Topic Map
[1] // Initialise the TMCore connection using applicaton configuration settings
[2] ITopicMapSystem tmSystem = TopicMapSystemFactory.GetTopicMapSystem();
[4] // Create a new topic map to work in
[5] ITopicMap tm = tmSystem.CreateTopicMap("http://www.example.com/topicmaps/MyFirstTopicMap");In line 2 the static method
TopicMapSystemFactory.GetTopicMapSystem() is
invoked to create and return a new
ITopicMapSystem instance. The
no-arguments version of GetTopicMapSystem()
uses the application's configuration file
(APIExample1.exe.config) to provide the necessary
configuration information. If you are running this application in the
Visual Studio.NET IDE, the file used is the file
App.config. An example
App.config is shown below. For a more in-depth look
on whats happening here, please refer to the section called “ITopicMapSystem and TopicMapSystemFactory”. In line 4 a topic map
with the name "http://www.example.com/topicmaps/MyFirstTopicMap" is
created.
Example 3.2. Topic Map Application Configuration File
[1] <configuration>
[2] <appSettings>
[3] <add key="networkedplanet.tmcore.dbconnect"
[4] value="Data Source=localhost;Integrated Security=SSPI; Initial Catalog=topicmap" />
[5] </appSettings>
[6] </configuration>A topic map's name is a unique identifier for the topic map within the TMCore system. Because of this, if you ran an application with the above example code in it twice, you would get a TopicMapExistsException thrown on the second occasion, informing you that a topic map with the specified name already exists. Instead, you should write code that checks that you are not about to create a topic map with a name that is already in use and take the appropriate action if there is. So rather than use the simple code shown in Example 3.1, “Creating a Topic Map”, something like the following code should be invoked:
Example 3.3. Safely Creating a Topic Map
[1] private static ITopicMap SafeCreateTM(ITopicMapSystem tms, string name)
[2] {
[3] ITopicMap tm = tms.GetTopicMap(name);
[4] if (tm != null)
[5] {
[6] tm.Remove();
[7] }
[8] return tms.CreateTopicMap(name);
[9] }
On line 3, an attempt is made to retrieve a topic map with the
base locator of the topic map we want to create. If a topic map is
found, we cannot create the new topic map directly. In this example, the
solution is simply to remove the topic map from the system. This is done
using the call to ITopicMap.Remove() on line 6.
The Remove() method removes the topic map and
all topics and associations that it contains from the system.
Alternatively you may choose to retry using some algorithm for
generating a new name string that does not already exist or perhaps even
prompt the application user for a new topic map name. Finally on line 8
the topic map is created. In this case, because any pre-existing topic
map with the same name has been removed, the call to the
CreateTopicMap() method will succeed.
Example 3.4. Creating and Populating Topics
[1] // Create topics
[2] ITopic t1 = tm.CreateTopic();
[3] t1.CreateTopicName("hello");
[4] t1.Save();
[6] ITopic t2 = tm.CreateTopic();
[7] t2.CreateTopicName("world");
[8] t2.Save();Creating a new topic in a topic map is as easy as calling the
CreateTopic() method on the ITopicMap instance.
The result of this method is a new ITopic
instance. The ITopic interface provides methods for creating new topic
names and occurrences. This is the pattern used throughout the TMCore
API - to create a new object, you call the appropriate
Create...() method on the parent object. Some
Create...() methods are overloaded with
different parameter lists to allow you to specify the content of the new
object, so in this example the call to
CreateTopicName() on lines 3 and 7 take a
single string parameter which is the string value of the newly created
ITopicName instance.
When an object is modified, the changes are not committed to the
topic map until the Save() method is called.
The Save() method is provided on the
ITopic and the
IAssociation interfaces only. To save a
change to a topic name or occurrence you must call the
Save() method on the containing
ITopic. To save a change to an
IAssociationRole instance you must call
the Save() method on the containing
IAssociation instance. Calling the
Save() method saves all of the changes made to
the ITopic or
IAssociation instance and the saving
takes place in a single database transaction - either all updates are
saved or, in the case of an error, none of the changes are saved.
In addition to Save() methods on
ITopic and
IAssociation, the
ITopicMap interface also provides a
Save() method. Invoking this
ITopicMap.Save() on a topic map will result in
all changes to contained ITopic and
IAssociation instances being committed in
a single transaction.
Example 3.5. Creating and Populating Associations
[1] // Create an association between the topics
[2] IAssociation a = tm.CreateAssociation();
[3] a.CreateAssociationRole(t1, null);
[4] a.CreateAssociationRole(t2, null);
[5] a.Save();Creating an association follows the same pattern as creating a
topic. The IAssociation instance is
created using the CreateAssociation() method of
the ITopicMap interface (line [2]).
IAssociationRole instances specify the
topics that participate in the association and are created using the
CreateAssociationRole() method of the
IAssociation interface. This method takes
two parameters, the first is the ITopic
that is participating in the association and the second is an
ITopic instance that specifies the type
of role played by the first topic in the association. Either of these
parameters may be null. As with the
ITopic interface, changes made are not
committed to the database until the
ITopic.Save() method is called.
Example 3.6. Looping over Topics and Associations
// Print out the names of each topic in the topic map
foreach(ITopic t in tm.Topics)
{
PrintTopicNames(t);
}
// Print out the role players of each association in the topic map
foreach(IAssociation assoc in tm.Associations)
{
PrintAssociation(assoc);
}
The ITopicMap interface provides
read-only properties Topics and
Associations. These return an
IList of the topics or associations in
the topic map. Although these properties make it extremely easy to
iterate over the contents of a topic map in a simple application like
this, with large topic maps any simple listing of all topics or all
associations will quickly become difficult to display and potentially
quite slow as you trawl through the whole database! However, for our
simple Hello World application, these properties are extremely
convenient.
Example 3.7. Accessing Topic Data
private static void PrintTopicNames(ITopic t)
{
System.Console.Write("Topic: ");
foreach(ITopicName tn in t.TopicNames)
{
System.Console.Write("{0} ", tn.Value);
}
System.Console.WriteLine();
}
Accessing data is as simple as using the properties defined by
each interface. In the example code above, the names of a topic are
returned by the ITopic.TopicNames property which is
a read-only IList of
ITopicName instances. The string value of
a topic name is accessed using the ITopicName.Value
property which is a read-write property.
The rule-of-thumb for whether a property will be read-only or
read-write is that if the property gives access to the parent or
children of an object, it will be read-only (you must use the
Create...() and
Remove() methods to manage parent-child
relationships). For other properties, access is read-write. So if we
wanted to update a topic name's string value it would be as simple as
:
tn.Value = "My New Name";
This small example showed how to create a topic map with 2 topics, named "hello" and "world", and an association between these topics. You can compile and run this example as described in the section called “Compiling and Running the Examples”. This example does not require any command line arguments.
The output of this example should be as shown below:
Topic : hello
Topic : world
Association Role Players:
Topic : hello
Topic : world
APIExample2 is a simple application which shows the basics of
using the programmatic indexes provided by TMCore. The program creates a
topic map from a directory (specified on the command line) and all its
subdirectories. For each directory and file in the hierarchy a topic is
created and assigned either the type "File" or "Directory" (these are
defined by separate topics created when the program first initialises).
For each file and for each subdirectory of the starting directory an
association is created to the containing directory. That association is
typed as "Parent-Child" with the containing directory playing a role of
type "Parent" and the contained file or directory topic playing the role
"Child". In addition, every file with a file name extension (eg.
MyFile.txt ) is also typed by a topic that describes the extension (e.g.
".TXT"). The first time that a file with a particular extension is
encountered, the typing topic is created. For each subsequent file with
the same extension, that same topic is used. To assign the right
extension type topic to a file topic, the
org.tmapi.index.core.TopicsIndex is used to look
up the extension type topic.
This example can be found in the file
examples/CS/APIExample2 for C# code and
examples/VB/APIExample2 for VB code.
Example 3.8. The Main Program Flow
public void Run(string startDirectory)
{
// Initialise a new ITopicMapSystem and create the topic map
m_tmSystem = TopicMapSystemFactory.GetTopicMapSystem();
m_tm = SafeCreateTM(m_tmSystem, "http://www.example.com/topicmaps/MyFileSystem");
// Add the basic topics required for creating our file-system topic map
CreateOntology();
ProcessDirectory(new DirectoryInfo(startDirectory), null);
ListTopicsAndAssociations();
ListTopicTypes();
ListDLLs();
}When the program is run, the name of the directory to process is retrieved from the command-line (not shown in the code above). This is passed into the main program loop as the parameter startDirectory. In the main program loop, the following is done:
A new TopicMapSystem is created and a new TopicMap is created in that system. This code is exactly the same as already discussed for APIExample1.
The CreateOntology() method is invoked to "bootstrap" the topic map with the topics that define the basic topic types of "File", "Directory" and the basic association type "Parent-Child" and role types "Parent" and "Child".
The ProcessDirectory() method is invoked to recurse through the directory specified by the startDirectory parameter, creating File and Directory topics and linking them together using Parent-Child associations.
All of the topics and associations created are listed to the console by the method ListTopicsAndAssociations(). This method makes use of code very similar to that already seen in APIExample1 and will not be covered in detail here.
All of the topics used to type other topics are listed to the console by the method ListTopicTypes().
All of the topics of a specific type (the type representing files with the .DLL extension) are listed to the console by the method ListDLLs();
Example 3.9. Creating the Topic Map Ontology
/// <summary>
/// Creates the topics for the basic types used by this topic map.
/// </summary>
private void CreateOntology()
{
// Topic to type all topics that represent files
m_tFile = CreateTopic("File", "http://www.networkedplanet.com/psi/examples/#File")
// Topic to type all topics that represent directories
m_tDirectory = CreateTopic("Directory", "http://www.networkedplanet.com/psi/examples/#Directory");
// Topics for creating the Parent/Child associations
m_tParent = CreateTopic("Parent", "http://www.networkedplanet.com/psi/examples/#Parent");
m_tChild = CreateTopic("Child", "http://www.networkedplanet.com/psi/examples/#Child");
m_tParentChild = CreateTopic("Parent-Child", "http://www.networkedplanet.com/psi/examples/#ParentChild");
}
/// <summary>
/// Utility method to create a topic with a single name and a
/// single subject identifier.
/// </summary>
/// <param name="name">The name to add to the new topic</param>
/// <param name="subjectIdentifier">The subject identifier URL for the new topic</param>
/// <returns>The newly created topic</returns>
private ITopic CreateTopic(string name, string subjectIdentifier)
{
ITopic ret = m_tm.CreateTopic();
ret.CreateTopicName(name);
if (subjectIdentifier != null)
{
ret.AddSubjectIdentifier(m_tm.CreateLocator(subjectIdentifier));
}
ret.Save();
return ret;
}
The above code shows one simple pattern for populating a new topic map with the basic typing topics for an application (often called an 'ontology'). The method CreateTopic() is used to create a single topic with a given name and subject identifier. This method is then invoked from the CreateOntology() method for each topic to be created. Of course, if your application will make use of the same topic map each time, you should check that a particular topic does not exist before creating a new one with the same subject identifier - we will see how to use indexes to achieve this in the next section. In this code, the topics are then stored as member variables of the main program class - in more complex applications you may want to create a specific "Ontology" class to manage these topics.
Example 3.10. Using Indexes
[1] /// <summary>
[2] /// Adds a topic representing a file into the topic map.
[3] /// </summary>
[4] /// <param name="fileInfo">The file to be processed.</param>
[5] /// <param name="parentDir">The topic representing the directory that contains this file.</param>
[6] private void ProcessFile(FileInfo fileInfo, ITopic parentDir)
[7] {
[8] // Create a topic representing the file
[9] ITopic fileTopic = m_tm.CreateTopic();
[10] fileTopic.AddType(m_tFile);
[11] fileTopic.CreateTopicName(fileInfo.FullName);
[12] fileTopic.CreateTopicName(fileInfo.Name, new ITopic[] {parentDir});
[14] if (fileInfo.Extension != null)
[15] {
[16] // Lookup the topic that represents this file's file extension
[17] string fileTypeIdentifier =
[18] "http://www.networkedplanet.com/psi/examples/extensions/#" +
[19] fileInfo.Extension.Substring(1).ToUpper();
[21] ITopic extensionType = m_tm.TopicsIndex.GetTopicBySubjectIdentifier(fileTypeIdentifier);
[22] if (extensionType == null)
[23] {
[24] // Create a topic to represent this files's file extension
[25] extensionType = m_tm.CreateTopic();
[26] extensionType.CreateTopicName("File Type: " + fileInfo.Extension.ToUpper());
[27] extensionType.AddSubjectIdentifier(fileTypeIdentifier);
[28] extensionType.Save();
[29] }
[30] fileTopic.AddType(extensionType);
[31] }
[33] fileTopic.Save();
[34] ...
[35] }The code snippet above shows part of the process of creating a
topic to represent a file. From line [14] to line [31] is code for
assigning a type to the file topic based on the extension of the file
name. So for example all files representing .DLL files will be typed by
a topic "DLL", all .TXT files by a topic "TXT" and so on. We want to be
sure that we only create the "DLL" or "TXT" topic on the first time we
encounter a file with that extension and not on subsequent files with
the same extension. The best way to identify topics is by assigning a
subject identifier to them. A subject identifier is simply a unique URI
identifier for the topic. In our example we create a subject identifier
with the URI
"http://www.networkedplanet.com/psi/examples/extensions/#{extension}".
Note that we force the file name extension to upper case to ensure that
"X.DLL" and "y.dll" both receive the same typing topic as subject
identifiers are case-sensitive. Having created a locator string with the
appropriate URL (lines [17]-[19]), we then look up the topic with that
subject identifier using the
TopicsIndex
. Every ITopicMap provides
access to a set of indexes of the different objects in the topic map.
All of these indexes are accessed through read-only properties of the
ITopicMap interface - they are easily
identified as each property name ends with "Index". Each of the indexes
provide a different set of look-up methods. The index we are using here,
the TopicsIndex provides methods to look up a topic
by its subject identifier, its subject locator, or its type(s). On line
21, the method
ITopicsIndex.GetTopicBySubjectIdentifier() is
invoked. Because a topic map can only ever have one topic with a given
subject identifier, this method will either return a single
ITopic instance or null. If the method
returns null, a new topic is created on lines 24-28. Finally the topic
(either the one returned by
GetTopicBySubjectIdentifier() or the newly
created topic) is added to the types for the file topic using the method
ITopic.AddType(), and the file topic is saved
to commit all the changes.
Example 3.11. Listing All Topic Types
[1] /// <summary>
[2] /// Displays the topics which are used to type other topics in the topic map.
[3] /// </summary>
[4] private void ListTopicTypes()
[5] {
[6] System.Console.WriteLine("All Topic Types:");
[7] IList topicTypes = m_tm.TopicsIndex.GetTopicTypes();
[8] foreach(ITopic t in topicTypes)
[9] {
[10] PrintTopicNames(t);
[11] }
[12] System.Console.WriteLine();
[13] }The example above shows another use of the indexes. In addition
to allowing you to look up objects by certain properties, most of the
indexes also allow you to do a reverse look up e.g. to quickly find
all topics which are used to type other topics. These reverse look up
methods can be extremely useful in constructing views and indexes for
the user. In this example the reverse look up is to find all topics
which are used to type other topics in the topic map and is achieved
on line [7] with a call to
ITopicsIndex.GetTopicTypes(), which returns
an IList of
ITopic instances.
This example program requires a single command line parameter which specifies the directory where the listing is to start. If this directory is not specified, it defaults to the working directory in which the application is run. The default value should enable the application to be run from within Visual Studio without having to modify the command line arguments property of the project.The output generated by the application will depend upon the directory you choose.
APIExample3 extends the file system topic map example from the previous section to show how XTM files can be imported into and exported from TMCore. The APIExample3 application :
Reads the basic ontology from an XTM file.
Writes the file system topic map to an XTM file.
Example 3.12. Reading An XTM File
/// <summary>
/// Reads the topics for the basic types used by this topic map.
/// </summary>
private void ReadOntology(string ontologyName, string tmName)
{
IXTMProcessor ixtmp = m_tmSystem.GetXTMProcessor();
ixtmp.ImportXTM(File.OpenRead(ontologyName),
new Uri("http://www.networkedplanet.com/examples/directory.xtm"),
tmName);
string idBase = "http://www.networkedplanet.com/psi/examples/";
m_tFile = GetTopic(idBase + "#File");
m_tDirectory = GetTopic(idBase + "#Directory");
m_tParentChild = GetTopic(idBase + "#ParentChild");
m_tParent = GetTopic(idBase + "#Parent");
m_tChild = GetTopic(idBase + "#Child");
}
The code example above shows how to import an XTM file into the
TMCore system. The import is done using an
IXTMProcessor instance. The
IXTMProcessor interface defines methods
for the import and export of XTM syntax topic maps from TMCore. An
IXTMProcessor instance is retrieved using the method
ITopicMapSystem.GetXTMProcessor(). The import
is performed using the ImportXTM method which has the following method
signature:
ITopicMap ImportXTM(System.IO.Stream input,
System.Uri srcLoc,
string name);
The parameter input specifies the stream
from which the XTM data is to be read. The stream may be from an open
file, from an HTTP connection or from any other data source that can
provide a stream. The srcLoc parameter
specifies the source URI for the data stream. The source URI is used
for the resolution of any relative paths found in the XTM data. For
example, in the code snippet above the srcLoc
parameter is specified as
"http://www.networkedplanet.com/examples/directory.xtm". If that XTM
file contained a reference "../index.html", then the reference would
be expanded to "http://www.networkedplanet.com/examples/index.html.
The source URI is also recorded in the
SourceLocators property of the
ITopicMap instance that receives the
XTM data. The name parameter specifies the name
of the topic map into which the data is to be imported. If a topic map
with the specified name does not already exist, it will be created. If
a topic map with the specified name does exist, then the topic map
data will be merged into the existing topic map.
Example 3.13. Writing An XTM File
private void WriteTopicMap(FileStream outputStream)
{
IXTMProcessor xtmp = m_tmSystem.GetXTMProcessor();
xtmp.ExportXTM(new StreamWriter(outputStream), m_tm);
}
The code example above shows that exporting a topic map as XTM data is even more straightforward. The method IXTMProcessor.ExportXTM() has the following signature:
void ExportXTM(System.IO.StreamWriter ouput,
ITopicMap tm);The parameter output provides a
StreamWriter instance that will output to the
stream on which the XTM data is to be written. This stream may connect
to a file or to any other sink which accepts streamed data. The
parameter tm specifies the
ITopicMap instance to be
exported.
This example program requires two command line arguments. The first specifies the path to the XTM file that provides the ontology for the application. If not specified, this first parameter defaults to the file "ontology.xtm" located in the current working directory. The second parameter specifies the directory from which the processing should start. If not specified, then this parameter defaults to the current working directory. These defaults should enable the application to be run from within Visual Studio without having to modify the command line arguments property of the project.
The output generated by the application will depend upon the directory you choose.
APIExample4 shows how to use the TMRQL query language from your own code. TMRQL is simply SQL applied to a defined set of relational views of your topic map data. This makes TMRQL easy to use for anyone already familiar with SQL and also has the advantage of extensive support in tools an in code from the .NET Framework.
The code in APIExample4 performs the following steps:
Import an XTM file into the database - this is the source data that will be queried. The source data is a partial genealogy of the British monarchy.
Execute a simple TMRQL query that finds all of the children of King William I (William the Conquerer) and list the IDs and names of the topics for those children.
Execute a more complex TMRQL query that makes use of a TMRQL-defined function that returns all descendants of King William I as a DataTable. That DataTable is then processed locally to create a simple tree view of the descendants.
The code for importing the XTM file is contained in the method
ImportXTMFile() - this is similar to the code
already seen in APIExample3 for XTM import.
The query for the direct children of William I is done in the
method QueryChildren(). In this query, we want to find all topics
associated with the topic for William I where the association type is
"child-of" and William I plays the role "parent". William I, "child-of"
and "parent" are all topics in the topic map an need to be found in the
database to perform this query. In this example, this is done as part of
th query itself, using the topic subject identifiers and looking up the
topic's unique identifiers using SQL sub-selects. The actual query
string used is slightly obscured by the use of string constants for the
base URIs of the subject identifiers, so is reproduced here in its
complete form except for the string {topicmap
ID} which is replaced with the
ObjectID of the
ITopicMap object passed into the
QueryChildren() method:
SELECT r2p, dbo.tm_displayName(r2p) FROM tm_assoc2 WHERE
topicmap = {topicmap ID} AND
r1p in (SELECT topic_id from tm_si where subj_id='http://www.example.com/psi/uk-monarchs/william-i') AND
association_type in (SELECT topic_id from tm_si where subj_id='http://www.example.com/psi/family/child-of') AND
r1t in (SELECT topic_id from tm_si where subj_id='http://www.example.com/psi/family/parent')The principal selection is done using the tm_assoc2 view which
presents pairs of topics that are in the same association, giving the
association type and the role type played by each topic. Each of the
topics William I, "child-of" and "parent" are found using a lookup in
the tm_si view which maps a topic's subject identifier to its unique
object identifier. In the SELECT part of the query, the tm_displayName
function is used to select one name from the topic specified in the
function parameter. The query is executed using the
ExecuteQuery() method of the
ITopicMapSystem interface, not on the
ITopicMap interface. Although this query
specifically restricts itself to a single topic map, but you can write
queries that span multiple topic maps in the same database (although you
will then need to be responsible for working out which results came from
which topic map!). The exection and procesing of the results set is
shown in the code snippet below.
ITMCoreDataReader dr = tm.TopicMapSystem.ExecuteQuery(query);
System.Console.WriteLine("Children of William I:");
try
{
while (dr.Read())
{
int id = dr.GetInt32(0);
string name = dr.GetString(1);
System.Console.WriteLine(" {0} - {1}", id, name);
}
}
finally
{
dr.Close();
}The ExecuteQuery() method returns an
instance of the ITMCoreDataReader
interface which extends the standard SQL DataReader implementation with
additional methods that can return full TMAPI objects from object
identifiers in the results set. As with a normal
DataReader, you can call the
Read() method to retrieve results row by row
until the method returns false (at which point you have reached the end
of the results set). You can then use the various
Get methods to
retrieve individual items from the row - in this case the unique object
identifier is retrieved as a 32-bit integer, and the topic name is
retrieved as a string.XXX()
Warning
You must always ensure that you call the
Close() method on the
ITMCoreDataReader interface when you
are done with it. Placing this call in the finally section of a try
block is the easiest way to ensure that the data reader is always
closed - even if an exception occurs when processing a row of the
results set.
The method QueryDescendents() prints a tree-view of all descendants of William I. This list is found by following the "child-of" associations (from "parent" role to "child" role") starting from William I. We call this traversal of a specific type of association in a specific direction (from one role type to another role type) as transitive closure. TMRQL provides two functions for retrieving this transitive closure. The tm_tc function is provided for backwards compatibility, but we recommend you use the tm_tc2 function which returns a table listing each path in the transitive closure as a pair of topics - the "from" topic and the "to" topic. If you think of the transitive closure like a tree, the "from" topic is the parent node and the "to" topic is the child node.
Note
Although it is often the case that these functions are used to retrieve tree structures, in fact the tm_tc and tm_tc2 functions are capable of handling cyclic references as well as straightforward hierarchies.
This method also shows a different way of constructing a query that requires topic identifiers. Rather than querying for the identifiers within the query string itself, the topics are first located using the Index APIs to lookup the topics one by one. This can be useful when you write a lot of queries that use the same topics over and over again. The code for the QueryDescendants() method is shown below.
string familyPsiBase = "http://www.example.com/psi/family/";
string monarchyPsiBase = "http://www.example.com/psi/uk-monarchs/";
ITopic childOf = tm.TopicsIndex.GetTopicBySubjectIdentifier(familyPsiBase + "child-of");
ITopic child = tm.TopicsIndex.GetTopicBySubjectIdentifier(familyPsiBase + "child");
ITopic parent = tm.TopicsIndex.GetTopicBySubjectIdentifier(familyPsiBase + "parent");
ITopic william = tm.TopicsIndex.GetTopicBySubjectIdentifier(monarchyPsiBase + "william-i");
string query = String.Format(
"SELECT from_id, to_id, dbo.tm_displayName(to_id) as child_name from tm_tc2({0},{1},{2},{3})",
william.ObjectID, childOf.ObjectID, parent.ObjectID, child.ObjectID);
try
{
ITMCoreDataReader dr = tm.TopicMapSystem.ExecuteQuery(query);
System.Data.DataTable tbl = dr.GetDataTable();
System.Console.WriteLine("William I:");
ListChildren(tbl, Int32.Parse(william.ObjectID), 2);
}
catch (Exception ex)
{
System.Console.WriteLine("ERROR: Caught error in processing query.");
System.Console.WriteLine(ex.ToString());
}The first 6 lines of the code are used to find the topics that are required to execute the tm_tc2 function. This function requires the identifiers of the starting topic for the closure, the type of the association to be traversed, the type of role played by the "from" topic at each link in the path and the type of role played by the "to" topic at each link. Because these topics are located first using the Index API, the query string can be much simpler - requiring only that the ObjectID of each topic be inserted into the correct place in the query. This code example differs from the previous query in another way too. Rather than reading the results set row by row, the code makes use of the GetDataTable() method provided by the ITMCoreDataReader interface. This method reads all the rows from the results set into a local System.Data.DataTable instance and then closes the DataReader. For large results sets, this could potentially require a lot of memory, but it has several advantages. Firstly it means that you do not have to explicitly close the DataReader as this is done by the code that constructs the DataTable. Secondly, the DataTable interface provides a number of methods that allow you to filter and select from the results data without executing further queries against the database. This second feature is used by the method ListChildren() which is a recursive method used to construct the tree view. Each time the ListChildren() method is invoked, it selects from the DataTable all those rows where the "from" topic identifier matches the identifier specified in the input parameter. Then for each row it prints the id and name of the "to" topic (the child) and then calls itself with the child topic identifier as the parameter to print the list of the child's children and so on. This code is shown in the snippet below.
private void ListChildren(System.Data.DataTable descendantsTable, int parentId, int indent)
{
System.Data.DataRow[] children = descendantsTable.Select("from_id=" + parentId, "child_name");
foreach(System.Data.DataRow childRow in children)
{
int childId = (int)childRow[1];
string childName = childRow[2] as String;
System.Console.WriteLine("{0}{1} - {2}", new String(' ', indent), childId, childName);
ListChildren(descendantsTable, childId, indent + 2);
}
}This example program requires a single command line argument that specifies the path to the XTM file that defines the data to be queried. The example file kings_and_queens.xtm contained in the source directory provides the data you need.
The output generated by the application using the topic map data provided should look like this (the topic identifiers will, of course, be different when you run the application, but the names should be the same):
Removing existing topic map...
Importing XTM file kings_and_queens.xtm. Please wait...
XTM import was successful!
Children of William I:
2612 - Adela
2566 - Robert Curthose, Duke Of Normandy
2598 - William II
2596 - Henry I
William I:
2612 - Adela
2606 - Stephen
2596 - Henry I
2592 - Matilda, Daugher Of Henry I
2580 - Henry II
2582 - John
2676 -
2602 - Richard I
2600 - William, Son of Henry I
2566 - Robert Curthose, Duke Of Normandy
2598 - William IIYou will have seen from the previous section, that coding TMRQL statements can require quite a lot of work in locating the topics that are input parameters into each query. You either end up writing code to find the topics using the Index API or you need to write long TMRQL queries that use sub-selects to find the topics. Most of the time, these topics are related to the system of topic, association, role and occurrence types in your topic map data and should be assigned URI subject identifiers to enable them to be found in the database. The ApplicationOntology object gives you a convenient API for managing these topics as well as an efficient local cache that can both improve query performance and make TMRQL queries more readable. You can read more about the ApplicationOntology object in the section called “The ApplicationOntology Object”. For the purposes of this section, you can think of the ApplicationOntology as a special form of cache in which short string keys can be used to retrieve full ITopic instances. The keys used can be directly tied to the URIs assigned to the topics in the topic map.
APIExample5 is a rewrite of APIExample4 using the ApplicationOntology object. The main order of processing is now:
Import the XTM source file.
Initialise the ApplicationOntology cache.
Perform the two queries as before but using the ApplicationOntology object to find the input topics.
The initialisation of the ApplicationOntology object is performed in the method GetApplicationOntology(). The code for this method is shown below.
private ApplicationOntology GetApplicationOntology(ITopicMap tm)
{
// Retrieve the inner ontology from the app settings file.
ApplicationOntology innerOnt = System.Configuration.ConfigurationSettings.GetConfig("ontology") as ApplicationOntology;
innerOnt.AddTopicMap(tm);
// Create an outer ontology with the inner ontology nested.
ApplicationOntology outerOnt = new ApplicationOntology(innerOnt);
outerOnt.AddPrefix("monarchs", "http://www.example.com/psi/uk-monarchs/");
outerOnt.AddTopicMap(tm);
return outerOnt;
}This code shows three important features of the ApplicationOntology object. Firstly an ApplicationOntology object can be constructed from the configuration settings for an application. This allows users to specify their ontology mappings using XML in the application's .config or Web.config file. Secondly, an ApplicationOntology can be intialised purely in code - this allows you to write code that uses specific mappings regardless of configuration file settings. Finally, ApplicationOntology objects can be nested one inside another - if the outer object cannot map an key to an ITopic instance, it passes the request to its nested ApplicationOntology object (which can in turn pass the request to its nested ApplicationOntology object and so on).
This code also shows how much of the cache mapping of the ApplicationOntology object works. You do not need to specify a cache key for every topic (although you can if you want to). Instead you declare a prefix string and the URI prefix that it maps to. You can then look up a topic using the prefix string followed by a colon and the rest of the URI. The ApplicationOntology will then expand the prefix and rest of URI into a full URI and search for a topic with that expanded URI as its subject identiifer. So in the code example above we add a prefix string "monarchs" for the URI prefix "http://www.example.com/psi/uk-monarchs/" - we can then find the topic for William I using the cache key "monarchs:william-i" which gets expanded to "http://www.example.com/psi/uk-monarchs/william-i" and locates the topic with that URI as a subject identifier. Once an ApplicationOntology object performs this expansion and finds a match, it then caches the direct topic reference, meaning that all future requests for the same item can be resolved without a look-up in the database. When you use the same topics time after time, this can provide a significant performance boost.
Looking up a topic using a cache key is simple in code - the ApplicationOntology acts like a normal .NET dictionary, returning ITopic instances from string keys, so you can write look-up code like this:
ITopic william = ontology["monarchs:william-i"];
However, the ApplicationOntology object also provides a method that assists in writing TMRQL statements by pre-processing them to replace cache key strings in curly braces with the object ID of the topic that is indexed against that cache key. This is shown in the QueryChildren() method by the following code:
private void QueryChildren(ITopicMap tm, ApplicationOntology ontology)
{
string query =
"SELECT r2p, dbo.tm_displayName(r2p) FROM tm_assoc2 WHERE" +
" topicmap = " + tm.ObjectID + " AND " +
" r1p={william} AND association_type={family:child-of} AND r1t={family:parent}";
query = ontology.ReplaceReferences(query);
try
{
ITMCoreDataReader dr = tm.TopicMapSystem.ExecuteQuery(query);
...The cache keys are written in the TMRQL statement surrounded by curly braces ({}). In this example the ApplicationOntology has been configured withs a direct mapping for the cache key "william" to the subject identifier "http://www.example.com/psi/uk-monarchs/william-i" as well as a prefix mapping for the string "family" to the URI prefix "http://www.example.com/psi/family/". The call to the ReplaceReferences() method of the ApplicationOntology object replaces these cache keys with the object identifiers of the topics "William I", "child-of" and "parent" respectively.
As you can see by comparing with the code from APIExample4, the ApplicationOntology object makes queries easier to write and to read and, because you avoid the need to do index lookups multiple times or to make use of SQL sub-selects in your queries, your code will execute faster too.
This example program requires a single command line argument that specifies the path to the XTM file that defines the data to be queried. The example file kings_and_queens.xtm contained in the source directory provides the data you need.
The output generated by the application using the topic map data provided should be the same as for APIExample4.
The TMCore API is divided into the following namespaces:
- NetworkedPlanet.TMAPI
Provides the interfaces that model the TMCore topic map system and the topic map data model supported by TMCore. These interfaces are described in more detail in Chapter 5, Core API.
- NetworkedPlanet.TMAPI.Index
Provides the interfaces for the principal object indexes supported by the TMCore API. The NetworkedPlanet.Index namespace contains only the base interface that defines operations common to all indexes. The sub-namespace NetworkedPlanet.Index.Core that contains the individual index interface definitions. See Chapter 6, Indexes for more information.
- NetworkedPlanet.TMAPI.Query
Provides interfaces for managing the results of executing a query against the TMCore topic map system. The query interfaces are described in Chapter 9, Querying.
- NetworkedPlanet.TMCore.Utils
Contains some useful utilities for accessing and manipulating topic maps. These utilities are described in more detail in Chapter 8, TMCore System Utilities.
- NetworkedPlanet.TMSyntax
Contains interfaces that model processors for importing and exporting topic maps from TMCore. For more information, please refer to Chapter 7, Importing and Exporting XTM Files.
- NetworkedPlanet.Npcl
Contains the APIs for the Networked Planet Constraint Language (NPCL). See Chapter 11, The NetworkedPlanet Constraint Language (NPCL) and Chapter 12, The NPCL Constraints API for more details.
The rest of this document is intended to give you an overview of all
of the facilities of the various APIs rather than to give a complete list
of every interface, class, method and property. For full detail on all
interfaces, classes, methods and properties defined by the API, please
refer to the HTML Help documentation contained in the file
doc\tmcore-api.chm.
Table of Contents
This package contains interfaces and classes that support the fundamentals of TMCore system programming:
Configuring and accessing a TMCore system. This is supported by the class TopicMapSystemFactory and the interface ITopicMapSystem.
A data model for topic maps and all of the objects found in topic maps, using the interface ITopicMapObject and all of its derived interfaces.
The interface
NetworkedPlanet.TMAPI.ITopicMapSystem
represents a connection to a TMCore system. In the TMCore system, the
topic maps that it manages are each assigned a unique identifier string
specifed by the Name property of the
ITopicMap instance. The property
ITopicMapSystem.TopicMapNames returns a
read-only IList containing the
Name property value of all topic maps that are
currently accesible through the
ITopicMapSystem. The
ITopicMapSystem method
GetTopicMap(String)is an access method to
retrieve an ITopicMap from the
ITopicMapSystem using the value of its
Name property as a key.
In addition, the ITopicMapSystem
interface allows you to create a new topic map in the TMCore system. To
create a new topic map, you will need to specify the unqiue name under
which the topic map should be stored. If you specify a name which is
already in use, a TopicMapExists exception will
be thrown.
An ITopicMapSystem instance cannot
be created directly, the TMCore API does not publicly expose a class
that implements this interface. Instead you must use the class
NetworkedPlanet.TMAPI.TopicMapSystemFactory to
configure and initialise an
ITopicMapSystem instance. The
configuration required for an
ITopicMapSystem is specified as a
collection of name/value pairs as shown in the following table:
Table 5.1. ITopicMapSystem Configuration Properties
| Property Name | Required? | Description |
| networkedplanet.tmcore.dbconnect | YES | The database connect string used to access the SQLServer instance that holds the TMCore system tables. |
| networkedplanet.tmcore.commandtimeout | NO | The number of seconds that a TMRQL command executed via
ITopicMapSystem.ExecuteQuery or
ITopicMapSystem.ExecuteQueries will
time out after. Default value is 15. |
The TopicMapSystemFactory class provides an
overloaded method GetTopicMapSystem() that
accepts this configuration information in a number of different ways.
The method GetTopicMapSystem() with no
arguments will configure the
ITopicMapSystem instance using the local
application configuration file. This file is an XML file that is named
either Web.config for web applications or
AppName.configMyApp.exe.config for an
application called MyApp.exe). The configuration
information must go in the <appSettings>
element of the config file. More information about the appSettings and
configuration files can be found here
on the Microsoft MSDN site. An example of an application
configuration file is shown below:
Example 5.1. A simple .config file for a TMCore Application
<?xml version="1.0" encocing="utf-8" ?>
<configuration>
...
<appSettings>
<add key="networkedplanet.tmcore.dbconnect"
value="Data Source=localhost;Integrated Security=SSPI; Initial Catalog=topicmap" />
...
</appSettings>
...
</configuration>
If you wish to retrieve the configuration information in some
other way, or wish to include a hard-coded set of configuration
parameters in your application, you can instead use the method
GetTopicMapSystem(NameValueCollection). The
NameValueCollection parameter contains the
property/value pairs to configure the
ITopicMapSystem that will be
returned.
In addition to enabling the creation and retrieval of topic
maps, ITopicMapSystem interface
provides methods and properties access to some TMCore system
utilities.
The method GetXTMProcessor() retrieves
an object implementing the IXTMProcessor interface that allows topic
map data to be imported into or exported from the TMCore system using
the standard XML Topic Maps (XTM) syntax. Import and export of XTM
files is covered in more detail in Chapter 7, Importing and Exporting XTM Files.
The method ExecuteQuery() is used to
execute an SQL query against the relational topic map data model
exposed by the TMCore system. This method returns an
ITMCoreDataReader instance. The
relational topic map model, querying and the
ITMCoreDataReader interface are dealt
with in Chapter 9, Querying.
The property ChangeNotifier returns an
instance of the IChangeNotifier
interface which can be used to monitor the TMCore system for
modifications made to topics and associations by any clients connected
to the system. The IChangeNotifier
interface is described in more detail in the section called “Change Notification”.
Each of the types of item defined by the topic maps data model is represented in the TMCore API by an interface. The names of the interfaces may be slightly unfamiliar to users of the XTM syntax because they are based on a more abstract model of a topic map called the "Topic Maps Data Model" (TMDM). This model is currently under development as part of the next version of ISO 13250 and so the TMCore interfaces cover both this model and a slightly modified version of it for XTM 1.0 topic maps. For more information about TMDM see the ISO Topic Maps website.
Understanding the TMCore containment hierarchy is the key to
working with the TMCore API. In a TMCore system, every object is
considered to be contained within one (and only one) other object. The
hierarchy is based on types, so all
ITopic instances are contained within
an ITopicMap instance; all
IOccurrence instances are contained
within an ITopic instance and so on.
The containment hieararchy is shown below:
ITopicMapSystemITopicMapIAssociationIAssociationRole
ITopicIOccurrenceITopicNameIVariant
The containment hierarchy is important in three respects, object creation, object removal and commits to the TMCore system.
An object can only be created as a child of its parent in the
containment hierarchy. This means that there are no public
constructors for any of the TMCore interfaces, instead you must use
the method CreateXXX() on the parent object
in the containment hierarchy where the XXX is replaced by the name of
the type of object you wish to create. For example, to create a topic,
call the method ITopicMap.CreateTopic() on
the ITopicMap instance that will
contain the new topic. Some of the
CreateXXX() methods are overloaded to provide
different ways of initialising the created object.
An object can never be detatched from its parent in the
containment hiearchy. The only way to remove an object from its parent
is to call the Remove() method on the object
itself. The Remove() method not only removes
the object from its parent, but also deletes it completely from the
TMCore system.
Finally, when an object in the containment hierarchy is
committed to the TMCore system using the
Save() method, changes to all of its children
in the containment hierarchy are also committed in a single
transaction. The Save() method is provided on
the ITopicMap,
IAssociation and
ITopic interfaces only, so to save a
change to an ITopicName instance, you
must call the Save() method on the containing
ITopic instance.
The ITopicMapObject interface is
the base interface for all interfaces that represent items in a topic
map and for the ITopicMap interface
itself. The ITopicMapObject interface
provides access to the SourceLocators property.
Source locators are identifiers for an
ITopicMapObject. When an object is
created as the result of importing an XTM file, a source locator is
assigned to that object if the corresponding XTM element had an ID
attribute value. The value is resolved to a complete URI relative to
the URI of the XTM data source being parsed. For example if an XTM
file is parsed from a source
"http://www.example.com/topicmaps/example1.xtm" and that file contains
an <association> element with the ID attribute "myAssoc", the
resulting IAssociation instance will have a source locator with the
value "http://www.example.com/topicmaps/example1.xtm#myAssoc". An
ITopicMapObject can have any number of
source locators, but it is an error for two different
ITopicMapObject interfaces in the same
topic map to have a common source locator. When an attempt is made to
assign a source locator to any
ITopicMapObject instance, the system
will raise a DuplicateSourceLocators exception
if there is another object in the same topic map with the same source
locator value, UNLESS both objects are topics, in which case the
topics will be merged.
The ObjectId property is a read-only string which specifies the unique identifier assigned to the object by the TMCore system.
The TopicMap property returns the
ITopicMap instance that this
ITopicMapObject instance is contained
in. If the object is itself an
ITopicMap, this property returns the
ITopicMap object it is invoked
on.
The ITopicMap interface provides
access to the basic properties of a topic map, including the topics
and associations that it contains and the indexes it provides. This
interface also defines a number of special methods.
The Topics and Associations properties are read-only properties which yield a read-only list of all topics or associations in the topic map.
The properties with names that end "...Index" provide direct access to the object indexes maintained by TMCore for the topic map. These indexes allow lookup of objects in the topic map by a variety of different properties of those objects. The indexes are covered in greater detail in the section called “The Core Indexes”.
The method
ITopicMap.MergeIn(ITopicMap) can be used to
merge one ITopicMap instance into
another. The ITopicMap on which the
method is invoked will be modified, gaining copies of all of the
topics and associations of the other
ITopicMap (with any merging required
also performed). The other ITopicMap
will not be modified in anyway by this method.
Every object in a TMCore database has a unique integer
identifier. The identifier is persistent across multiple sessions
and is only removed from the database as the result of a Remove()
method call or topic merging. The
ITopicMap interface provides two
convenience methods GetTopicByID(int id)
and GetAssociationByID(int id) to retrieve
ITopic and
IAssociation instances directly by
this database ID.
The following list shows the mappings that are made between XTM elements and TMCore interfaces and properties.
Whenever a
subjectIndicatorRefelement is encountered where its parent is not asubjectIdentityelement, it is mapped to a Topic with thesubjectIndicatorRefaddress as one of its SubjectIdentifiers property values or one of its SourceLocators property values.The
ITopicNameinterface and TopicNames property of theITopicinterface map to the XTMbaseNameelement.The SubjectLocators property of
Topicmaps to thesubjectIdentity/resourceRefelement.Note
Under the XTM 1.0 data model, a topic can only have one subject locator. However the proposed XTM 1.1 data model extends this to allow a topic to have multiple subject locators. In the TMCore API, the property is represented as an IList of strings to support this future extension.
The SubjectIdentifiers property of
ITopicmaps to thesubjectIdentity/subjectIndicatorRefelements.Each
IAssociationRoleinstance maps to one combination ofroleSpecandtopicReforsubjectIndicatorRefinside anassociation/memberelement. Thememberelement actually allows multipletopicReforsubjectIndicatorRefelements to appear after theroleSpec, however in TMCore system, these are "flattened" into a list of pairs of ITopic instances. For example given an association like this in XTM:<association> <instanceOf><topicRef xlink:href="#works-for"/></instanceOf> <member> <roleSpec><topicRef xlink:href="#employer"/></roleSpec> <topicRef xlink:href="#boulder-rock-company"/> </member> <member> <roleSpec><topicRef xlink:href="#employee"/></roleSpec> <topicRef xlink:href="#fred"/> <topicRef xlink:href="#barney"/> </member> </association>The resulting TMAPI representation would be an Association instance containing three AssociationRole instances (in its associationRoles property).
Nested
variantelements in XTM syntax are "flattened" in the TMCore API to a single level ofIVariantchildren of theITopicNameinstance. TheIVariantinstances have all the parameters specified on thevariantelement itself plus all those specified on its ancestorvariantelements.The list of parameters for a
variantcan be found in the Scope property of theIScopedObjectsinterface (which is a superclass of the IVariant interface).If the content of an
occurrenceorvariantis aresourceDataelement, then the string content of theresourceDataelement can be retrieved from the Value property of theIOccurrenceorIVariantinterface. If the content is aresourceRefelement, then the string which represents the address pointed to be theresourceReflink can be retrieved from the Resource property instead.
The TMCore API does not provide any explicit transaction control
methods. Instead, the TMCore system allows concurrent access using an
optimistic locking strategy. Under this strategy data is loaded from
the TMCore database without locking the rows in the database (allowing
any other application to concurrently access the data). Only when the
data is saved back to the database, is the database checked to ensure
that no other application modified the data in the intervening time.
If a modification did take place (known as a concurrent modification),
a ConcurrentModificationException is
raised and the updates that were attempted will be aborted. When a
call to ITopic.Save(),
IAssociation.Save() or
ITopicMap.Save() is made, all changes to the
object on which the Save() method was invoked
and all contained objects will be committed to the database in a
single transaction. This means that a call to
Save() will either succeed completely or fail
without modifying the database.
To minimize the chances of and the impact of concurrent
modification, it is strongly recommended that you tailor the commit
strategy for your application to the expected write patterns against
the topic map. If you anticipate frequent writes from multiple
separate threads, then try to keep the number of changes between calls
to the Save() method as small as possible.
This strategy will maximise the interleaving between applications and
minimize the amount of work you need to redo in the case of a
ConcurrentModificationException. If you
anticipate only infrequent writes or if you can isolate writes to one
thread or if you can isolate writer threads in a way that would
prevent them from writing the same objects in the topic map, then you
can afford to make more updates to the topic map between calls to
Save().
From TMCore05 SP2, the ITopic and
IAssociation interfaces both support a
method named Reload(). This method can be
used to update an ITopic or IAssociation instance from the database,
overwriting any local modifications with the most recent version of
the object from the persistent store. To recover from a
ConcurrentModificationException
therefore, you must first invoke the Reload()
method on the locally modified object, then reapply any local
modifications and finally invoke the Save()
method to save your changes to the persistent store.
Topic merging is handled automatically by TMCore under the following circumstances:
Two topics have at least one common string value in their SubjectLocators property.
Two topics have at least one common string value in their SubjectIdentifiers property.
Two topics have at least one common string value in their for the SourceLocators property.
One topic has a SubjectIdentifier property value that is in the SourceLocators property of another topic.
The need for merging is detected only when a topic is saved to the TMCore system. When merging takes place, the topic which was saved and whose modification is the cause of the merge receives all of the names and occurrences of the other topic and replaces that topic in all typing and scoping relationships. The other topic is then removed from the TMCore system. Any local reference to the removed topic is mapped through to the remaining topic automatically, but this only happens in the thread that caused the merging to take place. For all other threads, the changes will appear just as if one topic was modified and the other deleted from the system - any attempt to save changes to either of these topics after the merge occurred will result in a ConcurrentModificationException (assuming that the topics were initially retrieved from the system prior to the merge taking place).
Table of Contents
The namespace NetworkedPlanet.TMAPI.Index contains only a single interface, IIndex which defines the basic methods supported by all of the indexes provided from an ITopicMap instance. The namespace NetworkedPlanet.TMAPI.Index.Core contains interfaces which extend IIndex to provide methods for accessing indexed information about the objects in a topic map.
The interface IIndex defines a
generic interface for an index over the data in a single TopicMap
instance. The IIndex interface provides
methods for opening and closing an index; and for determining whether an
index is currently open or closed.
The methods IIndex.Open() and
Close() are used to modify the open state of
the index. The property IsOpen is a boolean value
which is true when the index is open. Calling any index retrieval
methods on an index which is not open will result in an exception being
thrown.
Note
The IIndex interface is defined for future extension to
implementations which may require local resources to be consumed when
an index is open. The SQLServer implementation of the TMCore API does
not consume any local resources. For the SQLServer implementation, all
indexes are automatically created as open and the
Close() method has no effect, hence the value
of the IsOpen property is always true.
The namespace NetworkedPlanet.TMAPI.Index.Core defines a
collection of index interfaces all of which are derived from
IIndex. Each of these index interface
provides additional methods for accessing indexed information about one
of the types of object in a topic map. The following table summarises
the core index interfaces and the indexes they provide access to.
Table 6.1. TMAPI Core Indexes
|
Index Interface |
Functionality |
|---|---|
|
|
Provides a list of all ITopics which define the type of one or more IAssociationRoles and an index of IAssociationRoles by their type. |
|
|
Provides a list of all ITopics which define the type of one or more IAssociations and an index of IAssociations by their type. |
|
| Provides a list of all ITopics which define the type of one or more IOccurrences; an index of IOccurrences by their type; an index of IOccurrences by their Resource property; and an index of IOccurrences by their Value property. |
|
| Provides a list of all ITopics which are part of the scope of one or more IScopedObjects (IAssociations, IOccurrences, ITopicNames and IVariants); and an index of IScopedObjects by their scoping topics. This index can be queried for all IScopedObjects with a specified ITopic as a scoping topic; all IScopedObjects with a specified collection of ITopics as part of their list of scoping topics (matching all the specified Topics) or all IScopedObjects with at least one of a specified collection of ITopics as one of their scoping topics. |
|
|
Provides an index of all ITopicMapObjects by their SourceLocators property. |
|
|
Provides an index of ITopicNames by their Value property. |
|
|
Provides a list of all ITopics which define the type of one or more ITopics; an index of ITopics by their SubjectIdentifiers; an index of ITopics by their SubjectLocators and an index of ITopics by their Types. The index of ITopics by Types allows you to retrieve either all ITopics with a specified ITopic in the Types property; all ITopics with a specified collection of ITopics in the Types property; or all ITopics with any one of a specified collection of ITopics in the Types property. |
|
| Provides an index of IVariants by their Resource property and an index of IVariants by their Value property. |
Table of Contents
The namespace NetworkedPlanet.TMSyntax contains a single interface
IXTMProcessor which provides methods for
the import and export of topic map data in XTM syntax. XTM data can be
imported to create a new topic map or to be merged into an existing topic
map.
This method allows topic map data to be imported from any stream into either an existing topic map or a new topic map within the TMCore system. The signature of the method is :
NetworkedPlanet.TMAPI.ITopicMap ImportXTM(System.IO.Stream inputStream,
System.Uri sourceLocator,
string name);The XTM data is read from the stream
inputStream. This stream may be from a local
file, from an HTTP or FTP connection or from any other data source that
supports the System.IO.Stream
interface.
The second parameter, sourceLocator,
specifies the URI address that is used for the resolution of any
relative links found in the XTM data. This parameter has a number of
effects on the addresses imported into the TMCore system:
The
sourceLocatorparameter value plus the value of theidattribute of thetopicMapelement (if any) will be added to the SourceLocators property of theITopicMapinstance into which the data is read. If thetopicMapelement has anidattribute value, then the source locator added will have a trailing # with theidattribute value, otherwise only the complete document path part of the URI will be used.e.g. If the
sourceLocatorparameter is "http://www.example.com/topicmaps/mymap.xtm" and the id attribute of thetopicMapelement is "tm", then the value of the locator added to the SourceLocators property will be "http://www.example.com/topicmaps/mymap.xtm#tm".Note
If the
sourceLocatorparameter has fragment and/or query parts such as "http://www.example.com/topicmaps/maps.asp?param=mymap", then these will be removed from the locator before adding the fragment id (if any) for thetopicMapelement.Any relative references in
resourceRefelements will be resolved against thesourceLocatorparameter value. This can be useful when you want to import from a local XTM file but have references to content resolve to a remote web server - as long as your XTM file has relative references, you can set thesourceLocatorparameter so that the resulting references imported into TMCore resolve to the remote server.For example if the topic map contains an
<occurrence>with a<resourceRef>which references the relative URI "../docs/mydoc.html" and that topic map is imported with thesourceLocator"http://www.example.com/topicmaps/mymap.xtm", then the reference stored in TMCore will be the fully resolved reference "http://www.example.com/docs/mydoc.html", even if the source stream is read from a local file.Any relative references to topics by a
topicRefelement and any references to other topic maps to be merged by amergeMapelement will be resolved against thesourceLocatorparameter. The import process will always attempt to merge all maps referenced from amergeMapelement and any external topic maps that contain topics referenced by atopicRefelement unless the address of the referenced topic map is already contained in the source locators for the current topic map (i.e. if that topic map was already imported and merged with the current topic map, it will not be imported again).
The final parameter, name, specifies the
name of the topic map into which the data will be imported. If this
parameter is null, then the name will default to the string value of the
sourceLocator parameter. If the name, after the
default value has been applied if necessary, matches the name of a topic
map that already exists in the TMCore system, then the data will be
merged into the topic map with that name. If the name does not match any
topic map already in the system, then a new topic map will be created.
In either case, the method will return an
ITopicMap instance that references the
topic map that was modified or created as a result of the import.
Example 7.1. Examples of Importing Into TMCore
// Import from a local file into a new topic map named after the file:
File f = new File("C:\topicmaps\import.xtm");
Uri srcLoc = new Uri(f.FullName);
IXTMProcessor xtmp = m_topicMapSystem.GetXTMProcessor()
Stream input = f.OpenRead();
ITopicMap tm = xtmp.ImportXTM(input, srcLoc, srcLoc.ToString());
input.Close();
The code above reads XTM data from a local file into a topic map with a name based on the file name. In line [2] a new File object is created using the path to the file to be imported. In line [3], that full name is converted into URI syntax (e.g. file:///c/topicmaps/import.xtm). In line [5] a new IXTMProcessor is retrieved from the TopicMapSystem. The import is performed in line [6], using the stream opened in line [5], the Uri representation of the full file path for resolution of any relative paths; and the same Uri (cast to a string) as the name of the topic map to be populated. The return from this call will be an ITopicMap instance representing the topic map that received the XTM data. Finally, the input stream must be closed by the local code as the ImportXTM method will not modify the open state of a stream.
// Import from a local file but resolve to remote references:
File f = new File("C:\topicmaps\import.xtm");
Uri srcLoc = new Uri("http://www.example.com/topicmaps/example1.xtm");
IXTMProcessor xtmp = m_topicMapSystem.GetXTMProcessor()
Stream input = f.OpenRead();
ITopicMap tm = xtmp.ImportXTM(input, srcLoc, srcLoc.ToString());
input.Close();
The code above also reads XTM data from a local file. However in this case, any relative URIs contained in the source XTM data will be resolved against the URI "http://www.example.com/topicmaps/example1.xtm".
The IXTMProcessor.ExportXTM() method
allows the content of a single topic map in the TMCore system to be
written to a stream in XTM syntax. The method has the following
signature:
void ExportXTM(System.IO.Stream writer,
NetworkedPlanet.TMAPI topicMap);The parameter writer specifies the output
stream writer that is to receive the XTM data and the parameter
topicMap specifies the
ITopicMap instance whose content is to be
exported.
Table of Contents
The namespace NetworkedPlanet.TMCore.Utils provides a small set of
utility classes for the TMCore system. With this release of TMCore, these
utilities provide a mechanism for one thread to monitor the changes made
in an ITopicMapSystem instance by all other
threads; a class for handling short string references to topics; and a
class for traversing hierarchies.
The change notification support of TMCore allows any thread to monitor the database for changes made by other threads to a specific topic map. The thread receives notification of the addition, removal or modification of all topics and associations in a topic map. Any changes to an object contained by a topic or association, including creation and removal are reported as a modification of the containing topic or association object.
The interface IChangeNotifier
defines an abstract interface for this change notification system. This
interface defines two events, AssociationChange
and TopicChange. These two events are both of
type ObjectChangeNotification which have the
following signature:
VB: Public Delegate Sub ObjectChangeNotification( _ ByVal objectID As String, _ ByVal topicmapID As String, _ ByVal changeType As ChangeType, _ ByVal changeID As Integer _ ) C#: public delegate void ObjectChangeNotification( string objectID, string topicmapID, ChangeType changeType, int changeID );
The objectID and
topicmapID parameters specify the unique
identifier of the object that was modified and of the topic map that
contains the modified object. The changeType
parameter is an enumerated type with the values CREATE, UPDATE and
DELETE to notify creation, modification and removal events respectively.
The changeID integer is a unique identifier for
this change event. The identifier is a simple incrementing integer and
so can be used to track the last event notified across multiple sessions
(e.g. to determine if the listener missed an event for some
reason).
The IChangeNotifier interface also
defines methods for starting and stopping the polling of the database.
The method StartPolling(long interval) begins
the polling of the database with an interval between polls specified in
milliseconds by the parameter interval. When the
startPolling() method is invoked, the first poll will be performed
immediately, with subsequent polls ocurring each time the polling
interval elapses. The method
StopPolling() can be used to halt polling
immediately. The method SetPollingInterval(long
interval) can be used to modify the polling interval while
the polling loop is running. The
IChangeNotifier implementation is
responsible for its own thread management, so the calling application
does not need to create a new thread to run the
IChangeNotifier instance in.
The change notification support of TMCore relies on a set of database triggers and tables to record the details of a change event. The triggers are used to log events to the tables, and the change notification system queries these tables to determine what the most recent changes are. Updating these tables adds an overhead to every update of the topic map and for some applications, where change polling is not a requirement, this overhead may be unecessary.
By default, a TMCore installation has change logging enabled. To
disable the change logging, the database owner must run the script
found at
INSTALL_DIR/scripts/disable-changelog.sqlINSTALL_DIR/scripts/enable-changelog.sql
Even if change logging is enabled, to maintain database performance we recommend that you periodically purge the change event logging tables. This can be done by executing the stored procedure TM_CLEAR_CHANGELOG. This procedure takes two optional parameters as described below:
- @tm
This integer parameter specifies the ID of the topic map to delete change log information for. If this parameter is not speciifed, then the change log information for all topic maps will be purged.
- @leaveLast
This integer parameter specifies the maximum number of rows to leave in each change log table after the purge. The value specifies the maximum difference between the ID of the highest change entry and the ID of the entries to leave in the log after purging. The purpose of this is to ensure that any applications that are polling the database for changes do not miss a log because it is created and then purged between polling cycles. This parameter defaults to a value of 1000 which should ensure that most applications with an average update frequency (100 additions, deletions and modifications per minute) and reasonably frequent polling frequency (of the order of 5 minutes between polling cycles) should not lose events, however if you have applications with a higher frequency of changes or which poll on a less frequent interval you should specify this parameter with a higher value.
Note
By default, permission to execute the TM_CLEAR_CHANGELOG procedure is granted only to the database owner role.
Every topic map application will be governed by its own unique topic map schema and its own unique system of topic instances. In most applications, the schema will be used to represent all the types of concepts presented by the site and the types of relationships between those concepts and between the concepts and other resources. You may also have a set of predefined topics that are used for classification purposes (often referred to as a taxonomy) - some more complex applications may include several taxonomies.
The class
NetworkedPlanet.TMCore.Utils.ApplicationOntology
provides a fast and convenient means of accessing the key topics that are
part of both the topic map schema and any taxonomies that govern your
application. Most importantly, the
ApplicationOntology class provides a string
replacement method that can be used in conjunction with the TMRQL query
language, allowing you to embed human-readable references to topics within
TMRQL queries without the need to do an explicit query of the subject
identifiers table.
Before you can use the ApplicationOntology
object effectively, you must assign a subject identifier to the topics you
wish to be accessible. A subject identifier is simply a unique URI
identifier for a topic.
Tip
We recommend that you only ever create new subject identifiers under a base URI that you have control over - doing this will avoid the potential for any future integration problems with other sources of topic map information. There is one exception to this rule though, and that is when you want to make use of the identifiers already defined by another individual or organisation.
The ApplicationOntology class works by taking
a configured list of mappings from short identifiers to full subject
identifiers and then using these full subject identifiers to look-up a
topic from one of a set of topic maps, returning the topic's unique object
ID. This shortening of identifiers can make your queries much easier to
read and also a lot shorter as it removes the need to explicitly look for
a topic by its subject identifier - you can simply insert the short
identifier for the topic in the place where you would normally have to
type the object identifier for the topic. In addtion, the
ApplicationOntology object caches successful
lookups to make subsequent requests for the same topic much faster than
embedding the lookup as part of a TMRQL query.
From a programming perspective, once it is configured the
ApplicationOntology object works like a read-only
Dictionary where the keys are short identifier strings and the values
return are ITopic instances.
The ApplicationOntology class supports two
forms of mapping between short identifiers and full subject identifiers.
The simplest form of mapping is simply to map a short identifier string to
a complete subject identifier. This simple form of mapping is useful for
one-off or small numbers of mappings, but in some cases you may have tens,
hundreds or even thousands of URIs to map. In this case you can make use
of the second form of mapping in which short identifier prefix is mapped
to subject identifier prefix. Once this mapping is made you can refer to a
full subject identifier by specifying the short prefix followed by the
remaining part of the identifier with a colon (:) separator. For example,
if you map the short identifier prefix "org" to the subject identifier
prefix "http://www.networkedplanet.com/2005/01/organisation/", then to
refer to the topic with the full subject identifier
"http://www.networkedplanet.com/2005/01/organisation/article", you would
use the short reference "org:article".
The Application Ontology object is configured in two steps. The first step is to define the mappings between short identifiers (or short identifier prefixes) and subject identifiers (or subject identifier prefixes), and the second step is to specify which topic map or topic maps should be searched for topics with the mapped subject identifiers during a look-up.
The definition of the mappings can be done using an XML fragment. This fragment can be part of a larger configuration file or a separate file itself. The TMCore library provides a helper class to allow you to embed the mappings as part of an application configuration (or web.config) file.
The format of the XML fragment is as follows:
<ontology> <identifierPrefix prefix="..." value="..."/> <subject key="..." identifier="..."/> </ontology>
- ontology
The root element for the configuration fragment.
- identifierPrefix
This element specifies a mapping between a short identifier prefix and a subject identifier prefix. The short identifier prefix is specified as the value of the
prefixattribute and the subject identifier prefix is specified as the value of thevalueattribute.- subject
This element specifies a mapping between a short identifier and a full subject identifier for a topic. The short identifier is specified as the value of the
keyattribute and the full subject identifier is specified as the value of theidentifierattribute.
Note
The ontology element may contain any number of
identifierPrefix or subject
elements in any order.
If you wish your application to use an Application Ontology object
configured from the application's configuration file, you can make use
of the application section handler that is part of the TMCore library.
To do this you will need to add the following line into the
configSections part of the application configuration
file:
<section name="ontology" type="NetworkedPlanet.TMCore.Utils.OntologySectionHandler, tmcore"/>
From within your code, you can then use this section handler to retrieve an instance of the NetworkedPlanet.TMCore.Utils.ApplicationOntology class that represents the configured Application Ontology. e.g.
ApplicationOntology ontology =
System.Configuration.ConfigurationSettings.GetConfig(
"ontology") as ApplicationOntology;If you wish to use the XML configuration from some configuration file other than the application configuration file, you must instead pass the XmlElement object that represents the ontology element to the constructor of the ApplicationOntology class. e.g.
ApplicationOntology applicationOntology;
XmlDocument configDoc = new XmlDocument();
configDoc.Load("myconfig.xml")
XmlElement ontologyElement = configDoc.SelectSingleNode("/config/ontology");
if (ontologyElement != null) {
applicationOntology = new ApplicationOntology(ontologyElement);
} else {
applicationOntology = new ApplicationOntology();
}
Finally, it is also possible to set up all of the mappings for the
Application Ontology directly from code. The methods for doing this are
ApplicationOntology.AddPrefix(string shortIdPrefix, string
subjectIdentifierPrefix) and
ApplicationOntology.AddIdentifier(string shortId, string
subjectIdentifier). e.g.
ApplicationOntology ontology = new ApplicationOntology();
ontology.AddPrefix("org", "http://www.networkedplanet.com/2005/01/organisation/");
ontology.AddIdentifier("title", "http://purl.org/dc/1.1/title");The second step in configuring an ApplicationOntology instance for
use is to specify the topic map or topic maps on which it operates.
These topic maps are the ones in which the Application Ontology object
will search for topics by their full subject identifier. The Application
Ontology object will search the topic maps it is connected to in strict
order, returning the first topic that matches. A topic map can be added
to the end of the search list using the method
ApplicationOntology.AddTopicMap(ITopicMap tm)
and can be removed using the method
ApplicationOntology.RemoveTopicMap(ITopicMap tm).
e.g.
ITopicMap coreMap = m_topicMapSystem.GetTopicMap("core.xtm");
ontology.AddTopicMap(coreMap)
Note
Whenever you add a new topic map to the search list for an ApplicationOntology instance or remove a topic map from its search list, the cache of topics found up until that point will be dropped. You should therefore avoid constantly reconfiguring the list of topic maps connected to an ApplicationOntology instance to maximise the potential for caching.
In some cases you may want to combine a predefined set of mappings that are set up programatically with a user-defined set of mappings which could be specified in an app.config or other XML configuration file. To support this you may nest one ApplicationOntology instance within another. Every ApplicationOntology instance supports just one nested instance. When an ApplicationOntology is asked to map a short identifier, it will first attempt to perform the mapping to a full subject identifier and then to a topic using its own configured mappings and topic maps, if that fails to find a match the short identifier will then be passed to the nested ApplicationOntology instance for it to resolve (and if that instance cannot resolve the short identifier, it will in turn pass the identifier on to its nested instance - if any - and so on).
The nested ontology can only be specified through the use of the appropriate constructor for the ApplicationOntology object. e.g.
// Get the inner ontology from the application configuration file
ApplicationOntology innerOntology =
System.Configuration.ConfigurationSettings.GetConfig(
"ontology") as ApplicationOntology;
// Create an outer ontology programatically:
ApplicationOntology outerOntology = new ApplicationOntology(innerOntology);
outerOntology.AddPrefix("org", "http://www.networkedplanet.com/2005/01/organisation/");
Note
It is still possible to use an ApplicationOntology instance which is nested inside another instance directly too, bypassing the outer ontology's lookups if necessary. In the example above your code could use either outerOntology (which adds a mapping for the prefix "org") or innerOntology to avoid the additional mappings specified by outerOntology.
The ApplicationOntology class provides two
basic modes of use: as a dictionary of values or as a string
filter.
To use the ApplicationOntology class as a
dictionary, simply index into it using short identifiers as you would with
any other IDictionary implementation. The
ApplicationOntology class returns an
ITopic instance if a match is found for the
short identifier and null otherwise. e.g.
// Create a new ontology with one prefix mapping and one short identifier mapping
ApplicationOntology ontology = new ApplicationOntology();
ontology.AddPrefix("org", "http://www.networkedplanet.com/2005/01/organisation/");
ontology.AddIdentifier("title", "http://purl.org/dc/1.1/title");
ontology.AddTopicMap(myTopicMap);
ITopic person = ontology["org:person"];
ITopic title = ontology["title"];
The ApplicationOntology class also provides
two methods which allow the class to act as a string processor. In this
mode, the input string is searched for tokens enclosed in curly braces.
These tokens are then matched against the
ApplicationOntology and if an
ITopic instance is returned, then the token
and the braces are replaced by the unique object identifier for the
ITopic instance. This is most useful in
processing TMRQL query strings prior to evaluating them. The method
ApplicationOntology.ReplaceReferences(string
input) works in exactly this way, but the method
ApplicationOntology.ReplaceReferences(string input, ITopic
focusTopic) will also match the tokens {FocusTopic} and
{TopicMap}, with the former being replaced by the unique object identifier
of the ITopic that is specified in the
focusTopic parameter and the latter being replaced
by the unique object identifier of the
ITopicMap instance that contains
focusTopic.
// Assuming ontology is already configured as shown in the previous example
// A query string containing a replacement value
string query = "select topic_id from tm_topic where type_id={org:person}";
// Expand the query using the application ontology
string expandedQuery = ontology.ReplaceReferences(query);
// Finally, execute the expanded query
ITMCoreDataReader dr = myTopicMapSystem.ExecuteQuery(expandedQuery);
The class
NetworkedPlanet.TMCore.Utils.HierarchyManager
provides a simple means of managing multiple topic hierarchies in a
topic map. The HierarchyManager class is capable
of scanning a topic map for all topic hierarchies which are defined in a
particular way and then extracting and caching the details of the
hierarchy in memory for fast access to the hierarchy of topics.
In order for the HierarchyManager class
to recognise a hierarchy, it is necessary to provide a
hierarchy topic which defines the hierarchy
itself. This hierarchy topic contains associations to:
the root topic of the hierarchy
a set of association type topics that will connect parent and child nodes.
a set of topics that represent the parent type roles between nodes of the hierarchy.
a set of topics that represent the child type roles between nodes of the hierarchy.
Two topics are connected to partipicate in a hierarchy in a parent-child relationship iff:
There is an association between the parent and child where the association type topic of the association is connected to the hierarchy topic.
There is an association between the parent and child where the parent topic plays one of the roles identified by the hierarchy topic.
There is an association between the parent and child where the child topic plays one of the roles identified by the hierarchy topic.
The hierarchy topic and the types of associations used to specify the root topic and the hierarchy association types all use a fixed set of PSIs which are defined by Techquila (see http://www.techquila.com/psi/).
In the model specified by Techquila, each hierarchy must be defined by a topic of type "Facet". This topic represents the entire hierarchy as a whole and so should be given a name that reflects the name of the whole hierarchy. This topic is not the root of the hierarchy - it only acts to define how to find the hierarchy and how to traverse it. The root of the hierarchy is identified using an association of the type "Facet-Has-Root". This association must be a binary association between the topic representing the hierarchy (playing the role "Facet") and the topic which is the root of the hierarchy (playing the role "Facet-Root"). The hierarchy must be constructed as a set of topics all connected together using the same type of association. The type of association used to construct the hierarchy is identified using an association of the type "Facet-Has-Hierarchy-Type". This association must also be a binary association between the topic representing the hierarchy (playing the role "Facet") and the topic which types the associations used to construct the hierarchy (playing the role "Facet-Hierarchy-Type"). Finally, the association roles played by the topics in the hierarchy must be divided into superordinate roles (i.e. the role played by the "parent" in the hierarchy) and subordinate roles (the role played by the "child" in the hierarchy). This is done by creating associations of type "Facet-Has-Superordinate-Role-Type" and "Facet-Has-Subordinate-Role-Type" between the facet topic and the topics defining the parent role type and child role type respectively.
All of the types described above have a Published Subject Identifier (PSI) defined for them by Techquila and summarised in the table below. If you follow the PSI URL you will be taken to pages which provide the official Techquila description for each of these topics.
Table 8.1. Topic PSIs for Topic Hierarchies
| Topic | PSI |
|---|---|
| Facet | http://www.techquila.com/psi/faceted-classification/#facet |
| Facet-Has-Hierarchy-Type | http://www.techquila.com/psi/faceted-classification/#facet-has-hierarchy-type |
| Facet-Hierarchy-Type | http://www.techquila.com/psi/faceted-classification/#facet-hierarchy-type |
| Facet-Has-Root | http://www.techquila.com/psi/faceted-classification/#facet-has-root |
| Facet-Root | http://www.techquila.com/psi/faceted-classification/#facet-root |
| Facet-Has-Subordinate-Role-Type | http://www.techquila.com/psi/faceted-classification/#facet-has-subordinate-role-type |
| Subordinate-Role-Type | http://www.techquila.com/psi/hierarchy/#subordinate-role-type |
| Facet-Has-Superordinate-Role-Type | http://www.techquila.com/psi/faceted-classification/#facet-has-superordinate-role-type |
| Superordinate-Role-Type | http://www.techquila.com/psi/hierarchy/#superordinate-role-type |
The diagram below shows this model in a schematic form.
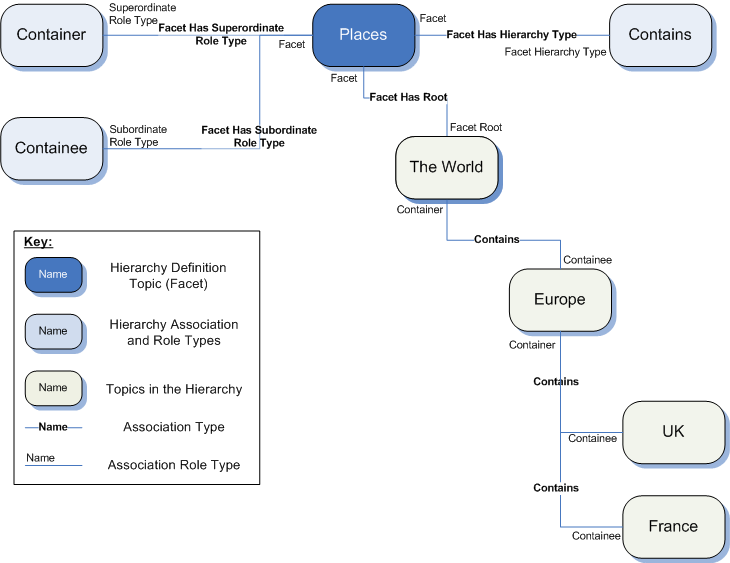
Although this may seem a little complex from the description above, it is actually very straightforward. The following procedure takes you through the process of defining a new hierarchy in an XTM topic map step by step.
Procedure 8.1. Creating a Topic Hierarchy
Create Or Import Techquila PSIs
This step only has to be performed once for each topic map and can be skipped by using
subjectIndicatorRefrather thantopicRefelements to refer to the Techquila topics. This can also be done through the TMCore Topic Map Editor web application or by invoking the staticCreateHierarchySchemaTopics(ITopicMap)method on theNetworkedPlanet.TMCore.Utils.HierarchyManagerclass.Create The Hierarchy Facet
This is the topic which defines the hierarchy as a whole. This topic must be an instance of the Techquila topic "Facet". In XTM this can be achieved as follows:
<topic id="places"> <instanceOf> <subjectIndicatorRef xlink:href="http://www.techquila.com/psi/faceted-classification/#facet"/> </instanceOf> <baseName> <baseNameString>Places</baseNameString> </baseName> <!-- Any other topic data --> </topic>Note
The
baseNameelements shown in this and all following examples are illustrative only - they are not required in constructing your hierarchy.Create The Hierarchy Root
This is the topic that will be at the root of the hierarchy. Hierarchies can only have a single root topic. The root topic can be of any type (or types) you like. For example:
<topic id="the-world"> <instanceOf><topicRef xlink:href="planet"/></instanceOf> <baseName> <baseNameString>The World</baseNameString> </baseName> </topic>To identify this topic as the hierarchy root, you must create a "Facet-Has-Root" association between the facet topic created in step 2 and this root topic:
<!-- The root of the "Places" hierarchy is "The World" --> <association> <instanceOf> <subjectIndicatorRef xlink:href="http://www.techquila.com/psi/faceted-classification/#facet-has-root"/> </instanceOf> <member> <roleSpec> <subjectIndicatorRef xlink:href="http://www.techquila.com/psi/faceted-classification/#facet"/> </roleSpec> <topicRef xlink:href="#places"/> </member> <member> <roleSpec> <subjectIndicatorRef xlink:href="http://www.techquila.com/psi/faceted-classification/#facet-root"/> </roleSpec> <topicRef xlink:href="#the-world"/> </member> </association>Specify The Hierarchy Association Type
All topics in our hierarchy must be associated with one another using a single type of association. The topic for that association type must be identified using a "Facet-Has-Hierarchy-Type" association between the facet topic created in step 2 and the association typing topic. For example:
<topic id="contains"> <baseName> <baseNameString>Contains</baseNameString> </baseName> </topic> <!-- The hierarchy association for "Places" hierarchy is "Contains" --> <association> <instanceOf> <subjectIndicatorRef xlink:href="http://www.techquila.com/psi/faceted-classification/#facet-has-hierarchy-type"/> </instanceOf> <member> <roleSpec> <subjectIndicatorRef xlink:href="http://www.techquila.com/psi/faceted-classification/#facet"/> </roleSpec> <topicRef xlink:href="#places"/> </member> <member> <roleSpec> <subjectIndicatorRef xlink:href="http://www.techquila.com/psi/faceted-classification/#facet-hierarchy-type"/> </roleSpec> <topicRef xlink:href="#contains"/> </member> </association>Specify the Subordinate and Superordinate Roles
The subordinate role is the role played by the child in a hierarchy association; the superordinate role is the role played by the parent. These are identified by creating additional associations between the topic that defines the hierarchy and the topics that define the subordinate and superordinate role types. So for our "Contains" association type, we have the role types "Container" (the superordinate role type) and "Containee" (the subordinate role type):
<!-- Container role is a superordinate role type --> <topic id="container"> <baseName> <baseNameString>Container</baseNameString> </baseName> </topic> <association> <instanceOf> <subjectIndicatorRef xlink:href="http://www.techquila.com/psi/faceted-classification/#facet-has-superordinate-role-type"/> </instanceOf> <member> <roleSpec> <subjectIndicatorRef xlink:href="http://www.techquila.com/psi/faceted-classification/#facet"/> </roleSpec> <topicRef xlink:href="#places"/> </member> <member> <roleSpec> <subjectIndicatorRef xlink:href="http://www.techquila.com/psi/hierarchy/#superordinate-role-type"/> </roleSpec> <topicRef xlink:href="#container"/> </member> </association> <!-- Containee role is a subordinate role type --> <topic id="containee"> <baseName> <baseNameString>Containee</baseNameString> </baseName> </topic> <association> <instanceOf> <subjectIndicatorRef xlink:href="http://www.techquila.com/psi/faceted-classification/#facet-has-subordinate-role-type"/> </instanceOf> <member> <roleSpec> <subjectIndicatorRef xlink:href="http://www.techquila.com/psi/faceted-classification/#facet"/> </roleSpec> <topicRef xlink:href="#places"/> </member> <member> <roleSpec> <subjectIndicatorRef xlink:href="http://www.techquila.com/psi/hierarchy/#subordinate-role-type"/> </roleSpec> <topicRef xlink:href="#containee"/> </member> </association>Create Hierarchy Associations
Now create as many hierarchy associations as necessary. When specifiying all the children of a single topic in the hierarchy you can use either one association with multiple subordinate role players or multiple binary associations. Note that these associations are completely free of the supporting topic infrastructure used to create the hierarchy. This means that any other topic map application that is not aware of the significance of the Techquila PSIs will still present the container/containee relationships as intended.
<!-- The World contains Europe --> <association> <instanceOf><topicRef xlink:href="#contains"/></instanceOf> <member> <roleSpec><topicRef xlink:href="#container"/></instanceOf> <topicRef xlink:href="#the-world"/> </member> <member> <roleSpec><topicRef xlink:href="#containee"/></instanceOf> <topicRef xlink:href="#europe"/> </member> </association> <!-- Europe contains UK and France --> <association> <instanceOf><topicRef xlink:href="#contains"/></instanceOf> <member> <roleSpec><topicRef xlink:href="#container"/></instanceOf> <topicRef xlink:href="#europe"/> </member> <member> <roleSpec><topicRef xlink:href="#containee"/></instanceOf> <topicRef xlink:href="#uk"/> <topicRef xlink:href="#france"/> </member> </association>
The class
NetworkedPlanet.TME.Utils.HierarchyManager
provides access to all of the hierarchies contained in a single topic
map. The constructor for the class takes a single
ITopicMap parameter which defines the
topic map which the manager should process. During the constructor,
the topic map is interrogated for all facets and the
HierarchyManager will attempt to process each
of those facets as a hierarchy. If the the subject identifiers
specified in Table 8.1, “Topic PSIs for Topic Hierarchies” are not all found in
the topic map, a ERROR level message will be written to the
HierarchyManager log (see Chapter 14, Logging for more details); a
TopicMapProcessingException will be
thrown and no hierarchies will be loaded. If some of the facets do not
conform to the structure required for a hierarchical facet, a WARNING
level message will be written to the
HierarchyManager log, but the correctly
structure facets will all be processed. The constructor code caches
the hierarchy in memory to provide rapid access to the entire
tree.
Once the HierarchyManager constructor
returns, the hierarchies found can be accessed through the
Hierarchies property. This returns an
unmodifiable IList of
NetworkedPlanet.TME.Utils.Hierarchy instances.
A Hierarchy instance represents the meta-data
for a hierarchy. This includes the
ITopic that defines the hierarchy and
the ITopic that defines the hierarchy
association type. In addition, the root node of the hierarchy can be
accessed through the Root property.
The Root property returns an instance of
NetworkedPlanet.TME.Utils.HierarchyNode. This
class is used to represent a single node in the hierarchy tree. The
property Topic provides access to the underlying
ITopic in the topic map and the
property Children returns an unmodifiable
IList of
HierarchyNode instances representing all of the
children of this node in the hierarchy. The properties
Parent and Hierarchy allow
direct access to the parent node in the hierarchy and the hierarchy
definition respectively.
To help users with understanding how to create and use the
HierarchyManager and its support classes:
HierarchyNode and
Hierarchy we have included an example
applications.
The C# example project may be found in the TMCore
examples\CS\HierarchyExample directory (no Visual
Basic version is supplied). For information about how to use the
TMCore examples, refer to the section called “Compiling and Running the Examples”.
The example creates a topic map representing a well-known family and the relationships between them. For simplicity only two associations types are considered: parenthood and siblings. The example then goes on to demonstrate how to create and navigate hierarchies using these family relationships.
Table of Contents
TMCore is built on relational database technology and exposes a complete relational data model for the topic maps managed by the system. The model consists of a set of views and pre-defined SQL functions which can be used to construct arbitrary queries across all topic map data using any of the SQL constructs supported by the underlying database - this includes statistical functions; data conversion fucntions; full-text query extensions and so on. Unlike the indexes covered in the section called “The Core Indexes”, the relational model also allows multiple topic maps to be queried simultaneously.
The TMCore engine installs a number of public views and user-defined functions into the SQL database. These views and functions are easily identified as they have names starting with the prefix "tm_". These views and functions are documented in the TMCore Query Reference Sheet.
Warning
You are strongly advised NOT to write queries which make use of the private tables and views as these may be subject to change either in structure or in content in future versions of the software and so an upgrade may cause your queries to function in unexpected ways.
You can use these views and functions in exactly the same way as you would use any normal SQL view or function. For example you can use the tm_displayName function to transform a topic id into a display name for the topic. For example the query:
select tm_displayName(r1p) from tm_assoc where association_id=123
would return the display name for each topic which plays a role in the association with the ID "123". Some of the functions defined by TMCore return table values which allows you to use them in a select or sub-select. For example you can use the tm_instanceOf function to return the classes and superclasses of a topic with a query such as:
select class_id from tm_instanceOf(tm, topic, NULL)
where tm and
topic should be replaced with the ID value of
the topic map and the instance topic respectively.
A full tutorial on the SQL query language is beyond the scope of this document. The TMCore Query Reference Sheet gives full documentation of each view and query provided by TMCore.
The interface ITopicMapSystem
provides a single method
ITopicMapSystem.ExecuteQuery(string) through
which an SQL query can be executed against the TMCore system. The method
returns an instance of the
ITMCoreDataReader interface which gives
read-only access to the results of the query.
The ITMCoreDataReader interface
extends the standard System.Data.IDataReader interface with the
following additional methods:
ITopic GetTopic(int i);ITopicName GetTopicName(int i);IOccurrence GetOccurrence(int i);IVariant GetVariant(int i);IAssociation GetAssociation(int i);IAssociationRole GetAssociationRole(int i);ITopicMapObject GetTopicMapObject(int i);Each of the methods listed above take as their single parameter
the zero-based position of the column from which the object's
ObjectID value is to be retrieved. The method then
loads any additional data required from the database and returns an
instance of the appropriate topic map object interface. The method
GetTopicMapObject() will determine the type of
the object and return an instance of the appropriate dervied interface
(e.g. an IOccurrence instance if the
identifier is from an occurrence object). If the content of the
specified column is not the object identifier of the requested type of
topic map object, then an InvalidCastException
will be raised.
Note
The GetTopicMapObject() method uses
additional database queries to determine the type of the object and so
its use should be avoided unless the specified column can contain
identifiers of a mixture of types of object.
As with other IDataReaders, the
ITMCoreDataReader must be closed once it
is no longer needed by calling the Close()
method. The TMCore code will create a new connection for each concurrent
ITMCoreDataReader instance that your
program holds open and unless these readers are closed when not needed,
your application will quickly use up all the available connections
leading to unexpected failures.
The code listing below shows an example of using the
ITopicMapSystem.ExecuteQuery() method to
retrieve the topic names which contain the string "foo" and have a
particular topic in their scope. Note that the call to the
ITMCoreDataReader.Close() method is enclosed in
the finally block to ensure that it gets called even if the processing
of a topic name results in an exception being raised.
Example 9.1. Using ITMCoreDataReader
ITopic scopingTopic;
ITopicMap tm;
// ... set up scopingTopic and tm
string query = "select v.name_id from " +
"TM_nameValue join TM_nameScope on TM_nameValue.name_id=TM_nameScope.name_id" +
"where TM_nameValue.name_value like '%foo%' and TM_nameScope.scoping_topic_id=" + scopingTopic.ObjectID;
ITMCoreDataReader dr = tm.TopicMapSystem.ExecuteQuery(query);
try {
while (dr.Read()) {
ITopicName tn = dr.GetTopicName(0);
// Do something with the scoped name
}
} finally {
dr.Close();
}
The TopicMapSystem interface also supports executing queries with a set of parameters. This is STRONGLY RECOMMENDED when one or more parameters come from user input as SQL parameter values are properly escaped and checked for SQL injection attacks. There are two overrides of the ExecuteQuery method that support parameters. The method ExecuteQuery(String queryString, IList parameters) takes a list of System.Data.IDataParameter instances (e.g. System.Data.SqlClient.SqlParameter), this method gives you the most control over the parameters you pass at the expense of requiring you to instantiate each parameter object explicitly. The second override is ExecuteQuery(String queryString, Hashtable parameters), which takes a Hashtable of parameter values where the Hashtable key is the parameter name and the value is the parameter value. The parameter type is automatically inferred from the parameter value.
The code samples below show how these two overrides can be used.
Example 9.2. Using ExecuteQuery(string, IList)
string query = "select v.name_id " + "from tm_nameValue join tm_nameScope on tm_nameValue.name_id=tm_nameScope.name_id "+ "where tm_nameValue.name_value like @name and tm_nameScope.scoping_topic_id=@scopingTopic"; ArrayList parameters = new ArrayList(); IDataParameter param = new SqlParameter(); param.Name = "@name"; param.DbType = DbType.String; param.Value = "%foo%"; parameters.add(param); param = new SqlParameter(); param.Name = "@scopingTopic"; param.DbType = DbType.Int32; param.Value = scopingTopic.ID; parameters.add(param); ITMCoreDataReader dr = tm.TopicMapSystem.ExecuteQuery(query, parameters);
Example 9.3. Using ExecuteQuery(string, Hashtable)
string query = "select v.name_id " + "from tm_nameValue join tm_nameScope on tm_nameValue.name_id=tm_nameScope.name_id "+ "where tm_nameValue.name_value like @name and tm_nameScope.scoping_topic_id=@scopingTopic"; Hashtable parameters = new Hashtable(); parameters["@name"] = "%foo%"; parameters["@scopingTopic"] = scopingTopic.ID; ITMCoreDataReader dr = tm.TopicMapSystem.ExecuteQuery(query, parameters);
The ITMCoreDataReader interface
provides two additional accessor methods which enable programmers to
work with the results of a query in different ways.
The method
ITMCoreDataReader.GetInternalDataReader()
returns the underlying IDataReader
instance that is wrapped by the
ITMCoreDataReader. For TMCore
applications connecting to a Microsoft SQL Server or MSDE database,
this IDataReader instance will be an
instance of the class
System.Data.SqlClient.SqlDataReader. In the
future, as other databases are supported, the value returned by this
method may be an instance of some database-specific implementation of
the IDataReader interface.
Note
Calling the Close() method on the
IDataReader returned by
GetInternalDataReader() will have the
side-effect of closing the
ITMCoreDataReader.
The method
ITMCoreDataReader.GetDataTable() reads
through the rows of the results set and creates and returns a
DataTable instance containing all of the
results. This method then closes the
ITMCoreDataReader, so no further reads
are possible. This method can be especially useful when working with
data bindings such as in ASP pages.
There are three keys to efficient use of the TMCore's query facilities:
Limiting the amount of data read in each results row.
Performing query analysis and indexing.
Make use of the ApplicationOntology cache object.
The helper methods GetTopic(),
GetAssociation() and so on retrieve all of
the data associated with the Topic or Association from either the
local object cache or (if not in the cache) from the database. This
retrieval requires additional queries and so can have a significant
impact on query performance. If you require only a small amount of
information (e.g. a topic name and an occurrence value), it is better
to construct your query to return just these values than to return the
ID of the topic and then use the GetTopic()
method and the API to retrieve the required values.
As the TMCore query language is simply SQL, it is possible to perform query analyses using standard tools such as the Query Analyzer that is part of the SQL Server toolset. Such tools can help indicate performance bottle-necks in a query. By default, the TMCore installation does not index any of the public views that can be used in your queries, so to boost query performance, you have two options:
Add indexes to the TMCore public views as indicated by your query analysis.
We do not recommend that you simply add indexes to all public views without first analyzing the most common and most time-consuming queries used by your system as over-use of indexes can impact database performance in other areas.
Create additional customised views using the TMCore public views as a source.
We do not recommend using the undocumented tables as a source for your customised views as these may change from one release of TMCore to another.
To aid analysis, you may want to log queries as they are executed by your application. These are logged as DEBUG messages in the log category networkedplanet.tmcore.system. Please refer to Chapter 14, Logging for more details.
The ApplicationOntology object (described in ) enables you to
write queries that use the unique object identifiers of topics without
having to write your own lookup and caching code. By using a single
ApplicationOntology object for your application
you can make use of the efficient caching of topic identifiers and you
can write your queries without having to include sub-queries to find
ontology-related topics. Use the
ReplaceReferences() method of the
ApplicationOntology class to replace cache key
references with topic identifiers in your query strings
Table of Contents
The TMAPI-based interfaces such as ITopic, IAssociation and so on provide methods for both topic map read and update. These interfaces are relatively efficient when the topics and associations you access are small and / or you are modifying all of the topic or association structure. This is because the implementations of these classes retrieve the entire topic or association from the database, perform any modifications locally and then only return the state to the database when you call the Save() method.
However there are many cases where an application is required to only perform some relatively small incremental update on a large number of topics or associations in a database and in those cases, the overhead of retrieving the entire structure for an ITopic or IAssociation instance from the database can cause performance problems. For these circumstances we have provided a transaction-oriented API for topic map updates.
Unlike TMAPI which deals with objects and object states, the transactional API deals with operations on a topic map. Each operation in the transactional API is processed by a database stored procedure call which updates some part of a topic or association. Individual calls are therefore processed much more quickly than if the equivalent operation was implemented using TMAPI.
The basic pattern for using the transactional API is simple:
Create an instance of the NetworkedPlanet.TMCore.Persistence.TransactionalPersistenceManager class.
The constructor takes an ITopicMapSystem instance as a parameter. So if you have an ITopicMap instance already, then you can use code like this:
// in the using section... using NetworkedPlanet.TMCore.Persistence; // in your code: TransactionalPersistenceManager tmpm = new TransactionalPersistenceManager(tm.TopicMapSystem);Use the TransactionalPersistenceManager to create a new NetworkedPlanet.TMCore.Transaction class instance. This is achieved by calling the StartTransaction method:
Transaction txn = tmpm.StartTransaction();
Make operation calls by invoking the methods of the Transaction class. See the API HTML Help file for a detailed description of each method. The sample code below creates a new topic and assigns a name and subject identifier to it. Note that the return values of the Transaction methods can be used in subsequent method calls in the same transaction, so it is possible to create a new topic and add names, occurrences and connect it into associations it all in a single transaction.
int personId = txn.AddTopic(tm.ID, personType.ID); // assume personType is an ITopic instance txn.AddTopicName(person, -1, "John Smith", null, null); txn.AddSubjectIdentifier(person, -1, "http://www.example.com/people/jsmith");
Commit all changes by calling the Commit() method of the Transaction instance or rollback changes by calling the Rollback() method.
// Sample structure for using a transaction Transaction txn = tmpm.StartTransaction(); try { // Call Transaction methods here txn.Commit(); } catch (Exception ex) { txn.Rollback(); // Handle exception or rethrow }
The transactional API is especially effective when used in combination with the query API. In this case you should execute the queries you need to determine what items need to be created, deleted or modified before then using the transaction API pattern described above to perform the updates. We recommend that you DO NOT attempt to execute queries with a transaction - firstly because this can significantly lenghten the time that you hold the transaction open, and secondly because queries are issued on a separate database connection which may lead to them being blocked by changes in your transaction that have not yet been committed.
The transactional API does not currently include any methods for updating topic names, variant names, occurrences or identifiers. The pattern for modifying one of these characteristics is to delete the old name, occurrence or identifier and then create a new one with the updated value.
Several of the methods of the Transaction class that identify items to be deleted from a topic map support the use of wildcard values to be passed in parameters. These methods should be thought of as selecting for deletion all those items that match the criteria specified in the parameters to the method. Where string values are matched, the SQL wildcard characters (% and _) are allowed, enabling you to select all occurrences with a string value that starts "Test" by passing "Test%" as the string match value for example. Where topics are matched, a value of -1 can be passed to match any topic.
The main exceptions to this rule are where the methods have a parameter that specifies the parent topic or association to be affected - in this case a non-negative object OID value is required; and also where the methods take an array of integers to define a scope - to match any scope (including the unconstrained scope), pass null as the value of the scope matching parameter, otherwise the scope you specify must exactly match the scope of the item to be deleted.
When using the transactional API, you should remember that every transaction you create is established in the context of its own database transaction. You should therefore be very careful to:
Always Commit() or Rollback() an Transaction when you are done with it.
Use try/catch blocks to ensure that you either Commit() the partially completed transaction or Rollback() the transaction if an exception is raised during processing.
Endeavour to keep transactions open for as short a time as possible - an open transaction can potentially block not only other database writers but also other database readers. If you have a large number of updates to perform we recommend that you break them down into smaller batches that each execute within a single transaction.
Table of Contents
TMCore supports provides a set of utility APIs for managing the definitions of a set of constraints on a topic map. Constraints can be used to define what types of topics and associations can be created, what types of associations a topic of a specific type can participate in, what types of occurences can be given to a topic of a particular type and also to constrain the values of occurrences of a specific type. Constraints enable both topic map validation and also the creation of more user-friendly editing interfaces. These constraints are expressed using the NetworkedPlanet Constraint Language (NPCL).
This release of TMCore provides support for retrieving and modifying constraints stored either in the topic map itself or as a separate XML file conforming to the NPCL XML Schema. This release DOES NOT provide methods for validating topic maps against a set of constraints or for enforcing validation of individual topics and associations when they are modified. Developers are free to create their own application-specific validation and enforcement routines based on the APIs provided.
The APIs are described in later chapters. This chapter deals with the structure of NPCL and its representation in XML and in a topic map.
This section introduces the key concepts of NPCL.
Every topic map consists of a set of topics, occurrences, associations and association roles. The Topic Maps model allows all of these constructs to be assigned a type. NPCL allows you to specify what types are present in your topic map, and what constructs each type can be used on. For example, it would allow you to say that the topic "Person" can be used as the type of other topics, but not as the type of an occurrence or association.
Types are specified by defining which meta-type they belong to. The meta-type is simply the topic map construct that the type can be applied to. NPCL defines the following 4 meta-types:
| Topic Type - types belonging to this meta-type can be used as the type of topics in the topic map. |
| Occurrence Type - types belonging to this meta-type can be used as the type of occurrence in the topic map. |
| Association Type - types belonging to this meta-type can be used as the type of associations in the topic map. |
| Role Type - types belonging to this meta-type can be used as the type of association roles in the topic map. |
Any type can belong to more than one meta-type. It is allowed, for example to say that the topic "Website" is both a Topic Type and an Occurrence Type.
Some of the meta-types allow type definitions to carry additional information in the form of facets. Facets are simply string properties with a special pre-defined meaning.
The following sections describe the facets defined by NPCL and how they are used.
This facet is found on Topic Types, Occurrence Types, Association Types and Role Types. Its value is a simple boolean string (either "true" or "false"). If the value is "true", this indicates that the type cannot be instantiated - that is that the user should be prevented from creating a topic, occurrence, association or role of that type. Although users cannot create instances of types marked as abstract, these types can still be used in the definition of constraints and these constraint definitions are then inherited by subclasses, which may be instantiated by users.
For example we may define an "Employment" association. We want to say that the "Employer" role can be played by either a "Person" or a "Company". Both "Person" and "Company" derive from a common superclass "Legal Entity". We can specify that "Legal Entity" is a Topic Type and then use it to define a Role Player Constraint that says that topics of type "Legal Entity" can play the role "Employer". However to force users to create topics that are either instances of "Person" or "Company" and to prevent them from creating topics of type "Legal Entity", we can add the Is Abstract facet to the type
This facet is found on Topic Types. It defines how instances of the Topic Type can be used in scoping other constructs in the topic map. Topics can be used to define the scope of topic names, occurrences or associations. By applying this facet to a Topic Type, you can specify that instances of the Topic Type can be used only to scope one of these constructs or any combination of them.
The string value of this facet should be one or more of the following strings (separated by spaces, tabs or carriage returns if you specify more than one).
- NAME
Indicates that topics of this type can be used to scope topic names.
- OCCURRENCE
Indicates that topics of this type can be used to scope occurrence on topics.
- ASSOCIATION
Indicates that topics of this type can be used to scope associations between topics.
For example, you may create a Topic Type "Language", the instances of this Topic Type would be topics such as "English", "French", "Klingon" and so on. It makes sense to allow the use of these topics to scope names and occurrences, but not much sense to allow them to scope associations as associations between topics are (almost always) language-independent. To specify this rule in NPCL, you simply add a Scoping Facet to the "Language" Topic Type with the value "NAME OCCURRENCE" (or "OCCURRENCE NAME" - the ordering is irrelevant).
By default, if no value is provided for the Scoping Facet of a Topic Type, it is assumed that instances of the Topic Type should not be used for scoping.
This facet is allowed on Occurrence Types. It defines the datatype of the value of any occurrence typed by the Occurrence Type. A datatype is simply the kind of value that is allowed on the occurrence - for example a "Date Of Birth" Occurrence Type might only allow values that are of a "date" datatype.
NPCL does not pre-define a set of datatypes. This is deliberate, as different applications and different topic map ontologies will have different requirements with regards to datatypes. However we recommend that unless you have unusual datatyping requirements, you should use the set of URI identifiers for datatypes that are defined by Part 2 of the W3C XML Schema specification (as noted in the schema for XML Schema Datatypes, the URI Identifier for a data type is simply the URI of the XML Schema namespace, followed by a fragment identifier which is the name of the datatype - e.g. http://www.w3.org/2001/XMLSchema#int.
These facets are allowed on Occurrence Types and are used to specify the lower and upper bound on the range of acceptable values for occurrences typed by the Occurrence Type. For example a "Batting Average" Occurrence Type might be given a Minimum Value facet of "0.0" and a Maximum Value of "1.0".
The Value Pattern facet is allowed on Occurrence Types and is used to specify a regular expression that defines the acceptable values for occurrences typed by the Occurrence Type. The regular expression should follow the syntax defined in Appendix F of Part 2 of the W3C XML Schema specification .
For example an occurrence of the Occurrence Type "Price" could be restricted to one or more digits followed by a decimal point and two further digits by setting the Value Pattern Facet for the "Price" Occurrence Type to "(\d)+.\d\d".
Constraints in NPCL specify the relationships that are allowed between instances of the types defined by the schema. NPCL has three kinds of constraints:
- Occurrence Constraints
Occurrence Constraints are allowed only on Topic Types. These constraints specify the types of occurrences that are allowed on a topic of a specific Topic Type.
- Role Player Constraints
Role Player Constraints are allowed only on Topic Types. They specify the types of roles in associations that can be played by a topic of a specific Topic Type.
- Association Role Constraints
Association Role Constraints occur only on Association Types. They specify the types of roles that can be present in an association of a specific Association Type.
All of the constraints support the Minimum Cardinality and Maximum Cardinality facets which specify a numeric limit on the number of relationships (e.g. the number of occurrences of type "Age" that can appear on a topic of type "Person" could be limited to a minimum of 0 and a maximum of 1). Some constraints provide additional rules about how topics can be related to each other. The following sections describe each constraint in more detail.
An Occurrence Constraint specifies that a topic of a specific Topic Type can have occurrences of a specific Occurrence Type. The Minimum Cardinality and Maximum Cardinality facets specify how many occurrences of the Occurrence Type are allowed on any single instance of the Topic Type.
A Role Player Constraint specifies that a topic of a specific Topic Type can play a role of a specific Role Type. These constraints can also optionally limit the roles played to only those in an association of a specific Association Type.
The Minimum and Maximum Cardinality facets constrain how many roles of the specified Role Type any instance of the specified Topic Type may participate in.
An Association Role Constraint specifies that an association of a specific Association Type can have a role of a specific Role Type.
The Minimum and Maximum Cardinality facets constraint how many roles of the specified Role Type can appear on any single instance of the specified Association Type.
Note
At this point it might seem confusing that there are limits on how many roles a topic can play and how many roles can appear in an association. However, the two controls apply in different circumstances. Consider a topic map in which we want to record people and the companies they work for. We want to record each Person-to-Company relationship as a separate association, but we recognise that a Company will have many employees and a Person may work for more than one company. We create topic types "Person" and "Company", association type "Employment" and Role Types "Employee" and "Employer". In this example, we would allow the Person Topic Type to play 0 or more roles of type "Employee" and the "Company" topic type to play 0 or more roles of type "Employer", using the Cardinality facets on the Role Player Constraints. However, to ensure that we keep each Person-Company relationship in a separate associaction, we would restrict the "Employment" Association Type to have exactly one role of type "Employer" and exactly one role of type "Employee" (set Minimum and Maximum Cardinality to "1").
The Association Role Constraint also supports an additional Arc Label Facet. This facet specifies a default human-readable label for the role. This label should be the way to describe the association relationship when seen from the point of view of the role player. For example an association describing the relationship between a person and the company they work for might be represented using the Association Type "Employment", with Role Types "Employee" and "Employer". This implies that there are two Association Role Constraints, one between the Association Type "Employment" and the Role Type "Employee" and the other between the Association Type "Employment" and the Role Type "Employer". For the "Employee" Role Type, a suitable arc label might be "Works For" whereas for the "Employer" Role Type we might use "Employs".
NPCL provides limited support for inheritance from one type to another.
The rules for constraint inheritance are as follows:
A type inherits constraints from all superclasses of the same meta-type. A Topic Type inherits only from superclasses which are also Topic Types, an Occurrence Type inherits only from Occurrence Types and so on.
It is allowed for a type to have topics of different meta-types in its set of superclasses, they are just ignored for the purposes of determining inheritance.
Only constraints are inherited. Other aspects such as facets and extension values (described later) are not inherited.
Note
The most important effect of this rule is that datatype, Minimum Value, Maximum Value and Value Pattern facets are not inherited by Occurrence Types - you must always express these facets directly on each subclass type.
If multiple superclasses define the same constraint, the type will inherit a constraint with cardinality facets that satisfy all superclass definitions of the constraint. In other words, the minimum cardinality will be the highest value defined by any superclass, and the maximum cardinality will be the lowest value defined by any superclass. If the result is that the maximum cardinality drops below the minimum cardinality, this is reported as an error.
To support the creation of flexible type hierarchies, NPCL supports the concept of topics that are not Topic Types, Occurrence Types, Role Types or Association Types appearing in the type hierarchy. These topics are referred to as "Abstract Types". Abstract Types can be useful if you have a large, complex type hierarchy but want to limit which types can be created by users. . An abstract type is simply a topic that participates in the class hierarchy of an ontology, but is not itself one of the specific meta-types.
Note
An Abstract Type cannot participate in the definition of any constraints and does not have any facets. If you want to use a type in the type hierarchy to define a common set of constraints that are to be inherited by subclasses, create the type as an instance of one of the meta-types and set the Is Abstract Facet on that type to "true" to prevent users from creating instances of the type.
In addition to being able to specify that all instances of a Topic Type are allowed to be used in scopes (using the Scoping Facet as described above), NPCL allows you to specify that certain specific topics can be used in scopes (even if their Topic Type does not allow it). This is achieved by adding the special NPCL type "Scoping Topic" to the types for the topic(s) that can be used in a scope. In general we recommend that you only use this feature for controlled lists of scoping topics.
A set of NPCL constraints can be specified using an XML document conforming to the NPCL XML Schema. This representation of the NPCL constraints is separate from the representation of the constraints in a topic map and so does not simply use the XTM syntax. NPCL XML Schema is also a more compact representation of a set of NPCL constraints than the topic map representation and is more easily processed using standard XML tools such as XSLT. This section describes the NPCL XML Schema in detail. The W3C XML Schema representation is also included in the TMCore distribution and can be downloaded from the NetworkedPlanet website.
The namespace used for NPCL XML Schema is http://www.networkedplanet.com/schema/npcl. In the examples in the rest of this section, this namespace is assumed to be mapped to the namespace prefix "npcl".
This is the root element of the NPCL XML synax. It contains a single types element which in turn contains the various type definition elements.
<npcl:schema>
<npcl:types>
<npcl:abstractType ...> ... </npcl:abstractType>
<npcl:topicType ... > ... </npcl:topicType>
<npcl:occurrenceType ... > ... </npcl:occurrenceType>
<npcl:associationType ... > ... </npcl:associationType>
<npcl:roleType ... > ... </npcl:roleType>
<npcl:scopingTopic ... > ... </npcl:scopingTopic>
</npcl:types>
</npcl:schema>
- npcl:schema
The root of an NPCL schema definition.
- npcl:schema/npcl:types
The wrapper for all type definitions contained in the schema. This element is OPTIONAL. The children of this element are allowed to appear in any order.
- npcl:schema/npcl:types/npcl:abstractType
An OPTIONAL, REPEATABLE element describing a single Abstract Type in the schema.
- npcl:schema/npcl:types/npcl:topicType
An OPTIONAL, REPEATABLE element describing a single Topic Type in the schema.
- npcl:schema/npcl:types/npcl:occurrenceType
An OPTIONAL, REPEATABLE element describing a single Occurrence Type in the schema.
- npcl:schema/npcl:types/npcl:associationType
An OPTIONAL, REPEATABLE element describing a single Assoiation Type in the schema.
- npcl:schema/npcl:types/npcl:roleType
An OPTIONAL, REPEATABLE element describing a single Role Type in the schema.
- npcl:schema/npcl:types/npcl:scopingTopic
An OPTIONAL, REPEATABLE element describing a single Scoping Topic in the schema.
This element describes a single Abstract Type in the schema.
<npcl:abstractType id="...">
<npcl:subjectIdentifier>
SUBJECT IDENTIFIER
</npcl:subjectIdentifier>
<npcl:displayName> NAME </npcl:displayName>
<npcl:extension type="EXTENSION TYPE">
EXTENSION VALUE
</npcl:extension>
<npcl:subclasses> ... </npcl:subclasses>
</npcl:abstractType>
- npcl:abstractType/@id
REQUIRED. An internal identifier for the type. This is used only for reference purposes inside the NPCL XML document.
- npcl:abstractType/npcl:subjectIdentifier
REQUIRED, REPEATABLE. Contains a subject identifier URI for the type.
- npcl:abstractType/npcl:displayName
Contains a human-readable display label for the type.
- npcl:abstractType/npcl:extension
Contains a single typed extension value for the type. The value is the string content of this element. The type is specified as a URI in the
typeattribute of this elment.- npcl:abstractType/npcl:subclasses
Contains a list of the subclasses of this type. This element structure is described in detail below.
This element describes a single Topic Type in the schema. It contains the Occurrence and Role Player Constraints that apply to this Topic Type.
<npcl:topicType id="..." abstract="true|false">
<npcl:subjectIdentifier>
...
</npcl:subjectIdentifier>
<npcl:displayName>...</npcl:displayName>
<npcl:rolePlayerConstraint
roleTypeRef="..."
associationTypeRef="..."
minCardinality="..."
maxCardinality="..."/>
<npcl:occurrenceConstraint
occurrenceTypeRef="..."
minCardinality="..."
maxCardinality="..."/>
<npcl:extension type="...">
...
</npcl:extension>
<npcl:subclasses> ... </npcl:subclasses>
</topicType>
- npcl:topicType/@id
REQUIRED. An internal identifier for the type. This is used only for reference purposes inside the NPCL XML document.
- npcl:topicType/@abstract
OPTIONAL. A boolean value that indicates if this type is abstract. If not specified, this attribute value defaults to "false".
- npcl:topicType/npcl:subjectIdentifier
REQUIRED, REPEATABLE. Contains a subject identifier URI for the type.
- npcl:topicType/npcl:displayName
Contains a human-readable display label for the type.
- npcl:topicType/npcl:rolePlayerConstraint
This element specifies a single Role Player Constraint that applies to this Topic Type.
The
roleTypeRefattribute is REQUIRED and contains the internal identifier of the Role Type that is allowed by the Role Player Constraint. This must match the value of the id attribute on a roleType element in the NPCL XML document.The
associationTypeRefattribute is OPTIONAL and contains the internal identifier of the Association Type that is allowed by the Role Player Constraint. This must match the value of the id attribute on an associationType element in the NPCL XML document. If this attribute is ommitted, then the Role Player Constraint applies to all roles of the specified Role Type, regardless of the type of association they are in.The
minCardinalityattribute specifies the Minimum Cardinality Facet for the constraint. This attribute is REQUIRED and its value must be a non-negative integer.The
maxCardinalityattribute specifies the Maximum Cardinality Facet for the constraint. This attribute is REQUIRED and its value must be either a non-negative integer or the string value "unbounded" (indicating that there is no upper limit on this constraint.- npcl:topicType/npcl:occurrenceConstraint
This element specifies a single Occurrence Cosntraint that applies to this Topic Type.
The
occurrenceTypeRefattribute is REQUIRED and contains the internal identifier of the Occurrence Type that is allowed by the Occurrence Constraint. This must match the value of the id attribute on an occurrenceType element in the NPCL XML document.The
minCardinalityattribute specifies the Minimum Cardinality Facet for the constraint. This attribute is REQUIRED and its value must be a non-negative integer.The
maxCardinalityattribute specifies the Maximum Cardinality Facet for the constraint. This attribute is REQUIRED and its value must be either a non-negative integer or the string value "unbounded" (indicating that there is no upper limit on this constraint.- npcl:topicType/npcl:extension
Contains a single typed extension value for the type. The value is the string content of this element. The type is specified as a URI in the
typeattribute of this elment.- npcl:topicType/npcl:subclasses
Contains a list of the subclasses of this type. This element structure is described in detail below.
This element describes a single Occurrence Type in the schema. It contains the Datatype, Minimum Value, Maximum Value and Value Pattern Facets that apply to this Occurrence Type.
<npcl:occurrenceType id="..." abstract="true|false"
datatype="..."
minValue="..."
maxValue="..."
valuePattern="...">
<npcl:subjectIdentifier>
SUBJECT IDENTIFIER
</subjectIdentifier>
<npcl:displayName> NAME </npcl:displayName>
<npcl:extension type="...">
...
</npcl:extension>
<npcl:subclasses> ... </npcl:subclasses>
</occurrenceType>
- npcl:occurrenceType/@id
REQUIRED. An internal identifier for the type. This is used only for reference purposes inside the NPCL XML document.
- npcl:occurrenceType/@abstract
OPTIONAL. A boolean value that indicates if this type is abstract. If not specified, this attribute value defaults to "false".
- npcl:occurrenceType/@datatype
OPTIONAL. The Datatype Facet value. This attribute specifies the datatype for values of occurences of this type.
- npcl:occurrenceType/@minValue
OPTIONAL. The Minimum Value Facet value. Specifies the minimum allowed value for occurrences of this type.
- npcl:occurrenceType/@maxValue
OPTIONAL. The Maximum Value Facet value. Specifies the maximum allowed value for occurrences of this type.
- npcl:occurrenceType/@valuePattern
OPTIONAL. The Value Pattern Facet value. Specifies a regular expressiong that values of occurrences of this type must match.
- npcl:occurrenceType/npcl:subjectIdentifier
REQUIRED, REPEATABLE. Contains a subject identifier URI for the type.
- npcl:occurrenceType/npcl:displayName
Contains a human-readable display label for the type.
- npcl:occurrenceType/npcl:extension
Contains a single typed extension value for the type. The value is the string content of this element. The type is specified as a URI in the
typeattribute of this elment.- npcl:occurrenceType/npcl:subclasses
Contains a list of the subclasses of this type. This element structure is described in detail below.
This element describes a single Association Type in the schema. It contains the Association Role Constraints that apply to this Association Type.
<npcl:associationType id="..." abstract="true|false">
<npcl:subjectIdentifier>
...
</npcl:subjectIdentifier>
<npcl:displayName> ... </npcl:displayName>
<associationRoleConstraint
roleTypeRef="..."
minCardinality="..."
maxCardinality="..."
arcLabel="..."/>
<npcl:extension type="...">
...
</npcl:extension>
<npcl:subclasses> ... </npcl:subclasses>
</associationType>
- npcl:associationType/@id
REQUIRED. An internal identifier for the type. This is used only for reference purposes inside the NPCL XML document.
- npcl:associationType/@abstract
OPTIONAL. A boolean value that indicates if this type is abstract. If not specified, this attribute value defaults to "false".
- npcl:associationType/npcl:subjectIdentifier
REQUIRED, REPEATABLE. Contains a subject identifier URI for the type.
- npcl:associationType/npcl:displayName
Contains a human-readable display label for the type.
- npcl:associationType/npcl:associationRoleConstraint
Defines a single Association Role Constraint that applies to this Association Type.
The
roleTypeRefattribute is REQUIRED and contains the internal identifier of the Role Type that is allowed by the Association Role Constraint. This must match the value of the id attribute on a roleType element in the NPCL XML document.The
minCardinalityattribute specifies the Minimum Cardinality Facet for the constraint. This attribute is REQUIRED and its value must be a non-negative integer.The
maxCardinalityattribute specifies the Maximum Cardinality Facet for the constraint. This attribute is REQUIRED and its value must be either a non-negative integer or the string value "unbounded" (indicating that there is no upper limit on this constraint.The
arcLabelattribute specifies the Arc Label Facet for the constraint. This attribute is OPTIONAL and its value should be a human-readable label for the association, when displayed in the context of the player of the role identified by theroleTypeRefattribute.- npcl:associationType/npcl:extension
Contains a single typed extension value for the type. The value is the string content of this element. The type is specified as a URI in the
typeattribute of this elment.- npcl:associationType/npcl:subclasses
Contains a list of the subclasses of this type. This element structure is described in detail below.
This element describes a single Role Type in the schema.
<npcl:roleType id="..." abstract="true|false">
<npcl:subjectIdentifier>
...
</subjectIdentifier>
<npcl:displayName> ... </npcl:displayName>
<npcl:extension type="...">
...
</npcl:extension>
<npcl:subclasses> ... </npcl:subclasses>
</roleType>
- npcl:roleType/@id
REQUIRED. An internal identifier for the type. This is used only for reference purposes inside the NPCL XML document.
- npcl:roleType/@abstract
OPTIONAL. A boolean value that indicates if this type is abstract. If not specified, this attribute value defaults to "false".
- npcl:roleType/npcl:subjectIdentifier
REQUIRED, REPEATABLE. Contains a subject identifier URI for the type.
- npcl:roleType/npcl:displayName
REQUIRED. Contains a human-readable display label for the type.
- npcl:roleType/npcl:extension
OPTIONAL, REPEATABLE. Contains a single typed extension value for the type. The value is the string content of this element. The type is specified as a URI in the
typeattribute of this elment.- npcl:roleType/npcl:subclasses
Contains a list of the subclasses of this type. This element structure is described in detail below.
This element describes a single Scoping Topic in the schema.
<npcl:scopingTopic>
<npcl:subjectIdentifier>
...
</subjectIdentifier>
<npcl:displayName> ... </npcl:displayName>
<npcl:extension type="...">
...
</npcl:extension>
</roleType>
- npcl:scopingTopic/npcl:subjectIdentifier
REQUIRED, REPEATABLE. Contains a subject identifier URI for the type.
- npcl:scopingTopic/npcl:displayName
REQUIRED. Contains a human-readable display label for the type.
- npcl:scopingTopic/npcl:extension
OPTIONAL, REPEATABLE. Contains a single typed extension value for the type. The value is the string content of this element. The type is specified as a URI in the
typeattribute of this elment.
This element is allowed as a direct child of the abstractType, topicType, occurrenceType, associationType and roleType elements. It contains a list of all of the subclasses of the type defined by the parent element.
<npcl:subclasses>
<subclass direct="true|false" classRef="..."/>
</subclasses>
- npcl:subclasses/npcl:subclass
References a single subclass of the type.
The
directis OPTIONAL and indicates whether the referenced type is a direct subclass of this type or if it is an indirect subclass (a subclass of a direct subclass of the type). For importing and schema parsing, only direct subclasses are considered - indirect subclasses are optionally provided when exporting an NPCL schema for processing convenience. If omitted, the value defaults to 'true'.The
classRefattribute is REQUIRED and references the type that is a subclass of this type. The value of this attribute must be the value of the id attribute of an abstractType, topicType, occurrenceType, associationType or roleType element in the NPCL XML document.
A set of NPCL types and constraints can be represented in a topic map as a collection of topics, occurrences and associations. This feature enables a topic map to carry its own type and constraint information without the need to use any external files. It also enables the use of generic topic map editing and processing tools to create and update the type and constraint information for a topic map. This section describes how an NPCL schema can be represented in a topic map.
Note
Although we describe the NPCL representation in XML Topic Maps (XTM) syntax in this document, it is important to realize that most often you will be creating your schemas using either the NPCL XML Schema or using tools such as the Topic Map Editor - you will only very rarely need to create the XTM structures shown here yourself.
Meta-types are special NPCL-defined topics that are used to specify that a topic can be used to type other topics, associations, association roles or occurrences in a topic map. This is done by adding the meta-type topic as a type to the typing topic. The following meta-types are defined by NPCL:
Table 11.1. NPCL Meta Types
| Meta Type | Relative PSI | Description |
|---|---|---|
| Topic Type | meta-types/topic-type | A topic typed by this meta-type topic can be used as the type of other topics in the topic map. |
| Association Type | meta-types/association-type | A topic typed by this meta-type topic can be used to specify the type of one or more associations in the topic map. |
| Association Role Type | meta-types/role-type | A topic typed by this meta-type topic can be used to specify the type of one or more association roles in the topic map. |
| Occurrence Type | meta-types/occurrence-type | A topic typed by this meta-type topic can be used as the type of one or more occurrences in the topic map. |
| Scoping Topic | types/scoping-topic | A topic typed by this meta-type topic can be used as a scoping topic in the scope of an association, occurrence, name or variant name in the topic map. |
The Relative PSI column shows the PSI for the meta-type relative
to the base PSI http://www.networkedplanet.com/psi/npcl/. The
full PSI must be present as a subject identifier for the meta-type
topic. For example, to create a "Topic Type" meta-type, you must create
a topic which has a subject identifier with the URI
http://www.networkedplanet.com/psi/npcl/meta-types/topic-type.
Example 11.1. XTM For A Topic Type
The following example shows how a topic type meta-type is defined in XTM syntax.
<xtm:topicMap xmlns:xtm="..." xmlns:xlink="...">
<!-- 'person' can be used as a topic type -->
<xtm:topic id="person">
<xtm:instanceOf>
<xtm:subjectIndicatorRef
xlink:href="http://www.networkedplanet.com/psi/npcl/meta-types/topic-type"/>
</xtm:instanceOf>
...
</xtm:topic>
</xtm:topicMap>Alternatively you could create a full topic for the meta-type and reuse it throughout the topic map e.g.
<xtm:topicMap xmlns:xtm="..." xmlns:xlink="...">
<!-- Topic type meta-type -->
<xtm:topic id="topic-type">
<xtm:subjectIdentity>
<xtm:subjectIndicatorRef
xlink:href="http://www.networkedplanet.com/psi/npcl/meta-types/topic-type"/>
</xtm:subjectIdentity>
...
</xtm:topic>
<xtm:topic id="person">
<xtm:instanceOf>
<xtm:topicRef xlink:href="#topic-type"/>
</xtm:instanceOf>
</xtm:topic>
<xtm:topic id="company">
<xtm:instanceOf>
<xtm:topicRef xlink:href="#topic-type"/>
</xtm:instanceOf>
</xtm:topic>
</xtm:topicMap>The Is Abstract Facet is represented as an occurrence of a special NPCL-defined type that can be added to a type topic. The PSI for this type is http://www.networkedplanet.com/psi/npcl/facets/is-abstract-facet. The value of the occurrence should be the string "true" if the type is abstract. Any other value for this occurrence will mark the type as NOT abstract (i.e. all other values of the occurrence are treated as "false").
Example 11.2. An Abstract Topic Type
<xtm:topicMap xmlns:xtm="..." xmlns:xlink="...">
<!-- Legal Entity is an abstract Topic Type -->
<xtm:topic id="legal-entity">
<xtm:instanceOf>
<xtm:subjectIndicatorRef
xlink:href="http://www.networkedplanet.com/psi/npcl/meta-types/topic-type"/>
</xtm:instanceOf>
<!-- Is Abstract Facet = true -->
<xtm:occurrence>
<xtm:instanceOf>
<xtm:subjectIndicatorRef
xlink:href="http://www.networkedplanet.com/psi/npcl/facets/is-abstract-facet"/>
</xtm:instanceOf>
<xtm:resourceData>true</xtm:resourceData>
</xtm:occurrence>
</xtm:topic>
</xtm:topicMap>The set of values allowed as resource data in an occurrence of a specific type can be defined by adding Value Facets to the occurrence type topic. These facets are added as occurrences of special NPCL-defined types that can be added to an occurrence type topic. The facets are described in the following table.
Table 11.2. Occurrence Type Value Facets
| Facet Name | Relative PSI | Description |
|---|---|---|
| Value Data-Type | facets/value-datatype-facet | Specifies the datatype that the occurrence value should match. The value of this facet occurrence must be a datatype URI. It is strongly recommended to only use the W3C Schema data type URIs, but applications may define their own data type URIs if needed. |
| Minimum Value | facets/minimum-value-facet | Specifies the minimum value that occurrence resource data must evaluate to. This facet is only consulted if the occurrence type also has a Value Data-Type facet and the data-type specified is a ranged data type (e.g. integer, float, date-time etc. but not string, ID etc.). |
| Maximum Value | facets/maximum-value-facet | Specifies the minimum value that occurrence resource data must evaluate to. This facet is only consulted if the occurrence type also has a Value Data-Type facet and the data-type specified is a ranged data type. |
| Value Pattern | facets/value-pattern-facet | Specifies a regular expression pattern that the occurrence resource data must match. |
Example 11.3. Occurrence Type Value Facets In XTM
The following example shows an occurrence type "Age" which is restricted to integer values between 0 and 125.
<xtm:topicMap xmlns:xtm="..." xmlns:xlink="...">
<xtm:topic id="age">
<xtm:instanceOf>
<xtm:subjectIndicatorRef xlink:href="htttp://www.networkedplanet.com/psi/npcl/meta-types/occurrence-type"/>
<xtm:instanceOf>
<xtm:baseName>
<xtm:baseNameString>Age (in years)</xtm:baseName>
</xtm:baseName>
<!-- data-type is integer -->
<xtm:occurrence>
<xtm:instanceOf>
<xtm:subjectIndicatorRef xlink:href="htttp://www.networkedplanet.com/psi/npcl/facets/value-datatype-facet"/>
</xtm:instanceOf>
<xtm:resourceData>http://www.w3.org/2001/XMLSchema#int</xtm:resourceData>
</xtm:occurrence>
<!-- minimum value is 0 -->
<xtm:occurrence>
<xtm:instanceOf>
<xtm:subjectIndicatorRef xlink:href="htttp://www.networkedplanet.com/psi/npcl/facets/minimum-value-facet"/>
</xtm:instanceOf>
<xtm:resourceData>0</xtm:resourceData>
</xtm:occurrence>
<!-- maximum value is 125 -->
<xtm:occurrence>
<xtm:instanceOf>
<xtm:subjectIndicatorRef xlink:href="htttp://www.networkedplanet.com/psi/npcl/facets/maximum-value-facet"/>
</xtm:instanceOf>
<xtm:resourceData>125</xtm:resourceData>
</xtm:occurrence>
</xtm:topic>
</xtm:topicMap>The topics of a particular type can be flagged for use in scopes using the Scoping Facet on the Topic Type topic. This facet is added as an occurrence of a special NPCL-defined type that can be added to a Topic Type topic. The PSI for this occurrence type is http://www.networkedplanet.com/npcl/facets/scoping-facet.
Example 11.4. Topic Type Scoping Facets In XTM
The following example shows an Topic Type "Language" which is restricted to scoping names and occurrence only.
<xtm:topicMap xmlns:xtm="..." xmlns:xlink="...">
<xtm:topic id="language">
<xtm:instanceOf>
<xtm:subjectIndicatorRef xlink:href="htttp://www.networkedplanet.com/psi/npcl/meta-types/topic-type"/>
<xtm:instanceOf>
<xtm:baseName>
<xtm:baseNameString>Language</xtm:baseName>
</xtm:baseName>
<!-- Language topics can scope topic names and occurrences -->
<xtm:occurrence>
<xtm:instanceOf>
<xtm:subjectIndicatorRef xlink:href="htttp://www.networkedplanet.com/psi/npcl/facets/scoping-facet"/>
</xtm:instanceOf>
<xtm:resourceData>NAME OCCURRENCE</xtm:resourceData>
</xtm:occurrence>
</xtm:topic>
</xtm:topicMap>Constraints in NPCL are always represented as topics. Constraint topics are typed using the following NPCL-defined topic types.
Table 11.3. NPCL Constraint Topic Types
| Constraint Type | Relative PSI | Description |
|---|---|---|
| Occurrence Constraint | constraints/occurrence-constraint | Constraints of this type define the types of occurrences that are allowed on specific types of topic. |
| Role Player Constraint | constraints/role-player-constraint | Constraints of this type define the types of association roles that can be played by specific types of topic. |
| Association Role Constraint | constraint/association-role-constraint | Constraints of this type define the types of association roles that can be present in associations of a specific type. |
Note
Relative PSIs are shown relative to the URI
http://www.networkedplanet.com/psi/npcl/
Each constraint topic is connected to two or more typing topics using associations as described in the sections below.
Every constraint has two facets. The Minimum Cardinality Facet specifies the minimum number of times that the relationship defined by the constraint should occur for each instance that it applies to. The Maximum Cardinality Facet specifies the maximum number of times that the relationship should occur. The table below makes this clearer for each constraint type.
Table 11.4. Minimum And Maximum Cardinality Facet Meanings
| Constraint Type | Minimum / Maximum Cardinality Facet Controls |
|---|---|
| Occurrence Constraint | The number of occurrences of a specific type that should occur on each topic of a specific type. |
| Role Player Constraint | The number of times a topic of a specific type can play a role of a specific type (optionally specific to one association type). |
| Association Role Constraint | The number of times a role of a specific type can appear in an association of a specific type. |
These facets are specified by adding occurrences to the
constraint topic. The occurrence type for a Minimum Occurrence Facet
must have the subject identifier
http://www.networkedplanet.com/psi/npcl/facets/minimum-cardinality-facet.
The occurrence type for a Maximum Occurrence Facet must have the
subject identifier
http://www.networkedplanet.com/psi/npcl/facets/maximum-cardinality-facet.
The Association Role Constraint also allows an Arc Label Facet where the facet value is a name for the association when viewed from the context of the role player. This facet value is NOT specified as an occurrence in XTM. Instead we use the common Topic Maps convention of specifying an arc label for an association using a base name on the association type, scoped by the role type. This is shown in the following example. To save space, the topics and associations that define the Association Role Constraints themselves are not shown (but a full example of this is given later in this chapter):
Example 11.5. The Arc Label Facet Expressed in XTM Syntax
<xtm:topicMap xmlns:xtm="...">
<xtm:topic id="employment">
<xtm:instanceOf>
<xtm:subjectIndicatorRef xlink:href="http://www.networkedplanet.com/psi/npcl/meta-types/association-type" />
</xtm:instanceOf>
<xtm:subjectIdentity>
<xtm:subjectIndicatorRef xlink:href="http://www.networkedplanet.com/npcl/tests/employment" />
</xtm:subjectIdentity>
<xtm:baseName>
<xtm:baseNameString>Employment</xtm:baseNameString>
</xtm:baseName>
<!-- Arc Label for the Employee Association Role -->
<xtm:baseName>
<xtm:scope><xtm:topicRef xlink:href="#employee"/></xtm:scope>
<xtm:baseNameString>Works For</xtm:baseNameString>
</xtm:baseName>
<!-- Arc Label for the Employer Association Role -->
<xtm:baseName>
<xtm:scope><xtm:topicRef xlink:href="#employer"/></xtm:scope>
<xtm:baseNameString>Employs</xtm:baseNameString>
</xtm:baseName>
</xtm:topic>
<xtm:topic id="employer">
<xtm:instanceOf>
<xtm:subjectIndicatorRef xlink:href="http://www.networkedplanet.com/psi/npcl/meta-types/association-role-type" />
</xtm:instanceOf>
<xtm:subjectIdentity>
<xtm:subjectIndicatorRef xlink:href="http://www.networkedplanet.com/npcl/tests/employer" />
</xtm:subjectIdentity>
<xtm:baseName>
<xtm:baseNameString>Employer</xtm:baseNameString>
</xtm:baseName>
</xtm:topic>
<xtm:topic id="employee">
<xtm:instanceOf>
<xtm:subjectIndicatorRef xlink:href="http://www.networkedplanet.com/psi/npcl/meta-types/association-role-type" />
</xtm:instanceOf>
<xtm:subjectIdentity>
<xtm:subjectIndicatorRef xlink:href="http://www.networkedplanet.com/npcl/tests/employee" />
</xtm:subjectIdentity>
<xtm:baseName>
<xtm:baseNameString>Employee</xtm:baseNameString>
</xtm:baseName>
</xtm:topic>
</xtm:topicMap>An Occurrence Constraint represents a restriction on the presence of occurrences of a defined type on topics of a defined type. Every Occurence Constraint must participate in the following associations.
Table 11.5. Associations Required To Specify An Occurrence Constraint
| Association Type (Relative PSI) | Constraint Role Type (Relative PSI) | Target Role Type (Relative PSI) | Target Topic Type (Relative PSI) |
|---|---|---|---|
Occurrence Constraint Applies To Topic Type
(constraints/oc-applies-to-tt) | Occurrence Constraint Applies To Topic Type Source Role
(constraint/oc-applies-to-tt-source) | Occurrence Constraint Applies To Topic Type Target Role
(constraints/oc-applies-to-tt-target) | Topic Type (meta-types/topic-type) |
Occurrence Constraint Allows Occurrence Type
(constraints/oc-allows-ot) | Occurrence Constraint Allows Occurrence Type Source
Role (constraints/oc-allows-ot-source) | Occurrence Constraint Allows Occurrence Type Target
Role (constraints/oc-allows-ot-target) | Occurrence Type
(meta-types/occurrence-type) |
Example 11.6. Example Occurrence Constraint
The following example shows an occurrence constraint that specifies that every Person topic has a single, optional Age occurrence.
<xtm:topicMap xmlns:xtm="..." xmlns:xlink="...">
<!-- Not shown : Definitions of person and age topics. -->
<!-- Person-Age Occcurrence Constraint -->
<xtm:topic id="person-age-constraint">
<xtm:instanceOf>
<xtm:subjectIndicatorRef
xlink:href="http://www.networkedplanet.com/psi/npcl/constraints/occurrence-constraint"/>
</xtm:instanceOf>
<!-- Person must have 0 or 1 Age occurrence -->
<xtm:occurrence>
<xtm:instanceOf>
<xtm:subjectIndicatorRef
xlink:href="http://www.networkedplanet.com/psi/npcl/facets/minimum-cardinality-facet"/>
</xtm:instanceOf>
<xtm:resourceData>0</xtm:resourceData>
</xtm:occurrence>
<xtm:occurrence>
<xtm:instanceOf>
<xtm:subjectIndicatorRef
xlink:href="http://www.networkedplanet.com/psi/npcl/facets/maximum-cardinality-facet"/>
</xtm:instanceOf>
<xtm:resourceData>1</xtm:resourceData>
</xtm:occurrence>
</xtm:topic>
<!-- Person-Age constraint applies to Person topic type -->
<xtm:association>
<xtm:instanceOf>
<xtm:subjectIndicatorRef
xlink:href="http://www.networkedplanet.com/psi/npcl/constraints/oc-applies-to-tt"/>
</xtm:instanceOf>
<xtm:member>
<xtm:roleSpec>
<xtm:subjectIndicatorRef
xlink:href="http://www.networkedplanet.com/psi/npcl/constraints/oc-applies-to-tt-source"/>
</xtm:roleSpec>
<xtm:topicRef xlink:href="#person-age-constraint"/>
</xtm:member>
<xtm:member>
<xtm:roleSpec>
<xtm:subjectIndicatorRef
xlink:href="http://www.networkedplanet.com/psi/npcl/constraints/oc-applies-to-tt-target"/>
</xtm:roleSpec>
<xtm:topicRef xlink:href="#person"/>
</xtm:member>
</xtm:association>
<!-- Person-Age constraint constrains occurrences of type Age -->
<xtm:association>
<xtm:instanceOf>
<xtm:subjectIndicatorRef
xlink:href="http://www.networkedplanet.com/psi/npcl/constraints/oc-allows-ot"/>
</xtm:instanceOf>
<xtm:member>
<xtm:roleSpec>
<xtm:subjectIndicatorRef
xlink:href="http://www.networkedplanet.com/psi/npcl/constraints/oc-allows-ot-source"/>
</xtm:roleSpec>
<xtm:topicRef xlink:href="#person-age-constraint"/>
</xtm:member>
<xtm:member>
<xtm:roleSpec>
<xtm:subjectIndicatorRef
xlink:href="http://www.networkedplanet.com/psi/npcl/constraints/oc-allows-ot-target"/>
</xtm:roleSpec>
<xtm:topicRef xlink:href="#age"/>
</xtm:member>
</xtm:association>
</xtm:topicMap>A Role Player Constraint represents a relationship between a topic type and an association role type that specifies the number of times a topic of the topic type can play a role of the association role type. A third, optional, element of this constraint is an association type. If present, then the constraint applies only to the number of times a topic of the topic type can play a role of the association role type in an association of the association type. These three elements of the constraint are indicated by three separate association types as shown in the following table.
Table 11.6. Associations Used To Specify A Role Player Constraint
| Association Type (Relative PSI) | Constraint Role Type (Relative PSI) | Target Role Type (Relative PSI) | Target Topic Type (Relative PSI) |
|---|---|---|---|
Role Player Constraint Applies To Topic Type
(constraints/rpc-applies-to-tt) | Role Player Constraint Applies To Topic Type Source
Role (constraint/rpc-applies-to-tt-source) | Role Player Constraint Applies To Topic Type Target
Role (constraints/rpc-applies-to-tt-target) | Topic Type (meta-types/topic-type) |
Role Player Constraint Allows Role Type
(constraints/rpc-allows-rt) | Role Player Constraint Allows Role Type Source Role
(constraints/rpc-allows-rt-source) | Role Player Constraint Allows Role Type Target Role
(constraints/rpc-allows-rt-target) | Association Role Type
(meta-types/association-role-type) |
Role Player Constraint Allows Association Type
(constraints/rpc-allows-at) | Role Player Constraint Allows Association Type Source
Role (constraints/rpc-allows-at-source) | Role Player Constraint Allows Association Type Target
Role (constraints/rpc-allows-at-target) | Association Type
(meta-types/association-type) |
Example 11.7. A Role Player Constraint Specified In XTM
The following example shows a single Role Player Constraint that says that a topic of type "person" can play the role of type "employee" in an association of type "employment". Note that no minimum or maximum cardinality is specified for the constraint. This means that the default cardinalities will be applied (0 for minimum cardinality and unbounded for maximum cardinality).
<xtm:topicMap xmlns:xtm="..." xmlns:xlink="...">
<!-- Not shown: Definitions of person, employee and employment topics -->
<!-- Person-Employee Role Player Constraint -->
<xtm:topic id="person-employee-constraint">
<xtm:instanceOf>
<xtm:subjectIndicatorRef
xlink:href="http://www.networkedplanet.com/psi/npcl/constraints/role-player-constraint"/>
</xtm:instanceOf>
</xtm:topic>
<!-- Person-Employee constraint applies to Person topic type -->
<xtm:association>
<xtm:instanceOf>
<xtm:subjectIndicatorRef
xlink:href="http://www.networkedplanet.com/psi/npcl/constraints/rpc-applies-to-tt"/>
</xtm:instanceOf>
<xtm:member>
<xtm:roleSpec>
<xtm:subjectIndicatorRef
xlink:href="http://www.networkedplanet.com/psi/npcl/constraints/rpc-applies-to-tt-source"/>
</xtm:roleSpec>
<xtm:topicRef xlink:href="#person-employee-constraint"/>
</xtm:member>
<xtm:member>
<xtm:roleSpec>
<xtm:subjectIndicatorRef
xlink:href="http://www.networkedplanet.com/psi/npcl/constraints/rpc-applies-to-tt-target"/>
</xtm:roleSpec>
<xtm:topicRef xlink:href="#person"/>
</xtm:member>
</xtm:association>
<!-- Person-Employee constraint constrains roles of type Employee -->
<xtm:association>
<xtm:instanceOf>
<xtm:subjectIndicatorRef
xlink:href="http://www.networkedplanet.com/psi/npcl/constraints/rpc-allows-rt"/>
</xtm:instanceOf>
<xtm:member>
<xtm:roleSpec>
<xtm:subjectIndicatorRef
xlink:href="http://www.networkedplanet.com/psi/npcl/constraints/rpc-allows-rt-source"/>
</xtm:roleSpec>
<xtm:topicRef xlink:href="#person-employee-constraint"/>
</xtm:member>
<xtm:member>
<xtm:roleSpec>
<xtm:subjectIndicatorRef
xlink:href="http://www.networkedplanet.com/psi/npcl/constraints/rpc-allows-rt-target"/>
</xtm:roleSpec>
<xtm:topicRef xlink:href="#employee"/>
</xtm:member>
</xtm:association>
<!-- Person-Employee constraint constrains roles in associations of type Employment -->
<xtm:association>
<xtm:instanceOf>
<xtm:subjectIndicatorRef
xlink:href="http://www.networkedplanet.com/psi/npcl/constraints/rpc-allows-at"/>
</xtm:instanceOf>
<xtm:member>
<xtm:roleSpec>
<xtm:subjectIndicatorRef
xlink:href="http://www.networkedplanet.com/psi/npcl/constraints/rpc-allows-at-source"/>
</xtm:roleSpec>
<xtm:topicRef xlink:href="#person-employee-constraint"/>
</xtm:member>
<xtm:member>
<xtm:roleSpec>
<xtm:subjectIndicatorRef
xlink:href="http://www.networkedplanet.com/psi/npcl/constraints/rpc-allows-at-target"/>
</xtm:roleSpec>
<xtm:topicRef xlink:href="#employment"/>
</xtm:member>
</xtm:association>
</xtm:topicMap>An Association Role Constraint specifies a relationship between an association type and an association role type that defines how many roles of the association role type can appear on an association of the association type. To specify an Association Role Constraint, two associations are required, one between the constraint topic and the association type topic and one between the constraint topic and the association role type topic. The table below provides details of the associations required.
Table 11.7. Associations Required To Specify An Association Role Constraint
| Association Type (Relative PSI) | Constraint Role Type (Relative PSI) | Target Role Type (Relative PSI) | Target Topic Type (Relative PSI) |
|---|---|---|---|
Association Role Constraint Applies To Association Type
(constraints/arc-applies-to-at) | Association Role Constraint Applies To Association Type
Source Role
(constraint/arc-applies-to-at-source) | Association Role Constraint Applies To Association Type
Target Role
(constraints/arc-applies-to-at-target) | Association Type
(meta-types/association-type) |
Association Role Constraint Allows Role Type
(constraints/arc-allows-rt) | Association Role Constraint Allows Role Type Source
Role (constraints/arc-allows-rt-source) | Association Role Constraint Allows Role Type Target
Role (constraints/arc-allows-rt-target) | Association Role Type
(meta-types/association-role-type) |
Example 11.8. An Association Role Constraint in XTM
The following example shows how to specify an Association Role Constraint in XTM syntax. The example shows a constraint the requires an association of type "employment" to have exactly one role of type "employee".
<xtm:topicMap xmlns:xtm="..." xmlns:xlink="...">
<!-- Not defined : The topics employment and employee. -->
<!-- Employment-Employee Constraint. -->
<topic id="employment-employee-constraint">
<xtm:instanceOf>
<xtm:subjectIndicatorRef
xlink:href="http://www.networkedplanet.com/psi/npcl/constraints/association-role-constraint"/>
</xtm:instanceOf>
<!-- Employment association must have exactly 1 employee role -->
<xtm:occurrence>
<xtm:instanceOf>
<xtm:subjectIndicatorRef
xlink:href="http://www.networkedplanet.com/psi/npcl/facets/minimum-cardinality-facet"/>
</xtm:instanceOf>
<xtm:resourceData>1</xtm:resourceData>
</xtm:occurrence>
<xtm:occurrence>
<xtm:instanceOf>
<xtm:subjectIndicatorRef
xlink:href="http://www.networkedplanet.com/psi/npcl/facets/maximum-cardinality-facet"/>
</xtm:instanceOf>
<xtm:resourceData>1</xtm:resourceData>
</xtm:occurrence>
</topic>
<!-- Employment-Employee constraint applies to Employment association type -->
<xtm:association>
<xtm:instanceOf>
<xtm:subjectIndicatorRef
xlink:href="http://www.networkedplanet.com/psi/npcl/constraints/arc-applies-to-at"/>
</xtm:instanceOf>
<xtm:member>
<xtm:roleSpec>
<xtm:subjectIndicatorRef
xlink:href="http://www.networkedplanet.com/psi/npcl/constraints/arcc-applies-to-at-source"/>
</xtm:roleSpec>
<xtm:topicRef xlink:href="#employment-employee-constraint"/>
</xtm:member>
<xtm:member>
<xtm:roleSpec>
<xtm:subjectIndicatorRef
xlink:href="http://www.networkedplanet.com/psi/npcl/constraints/arc-applies-to-at-target"/>
</xtm:roleSpec>
<xtm:topicRef xlink:href="#employment"/>
</xtm:member>
</xtm:association>
<!-- Employment-Employee constraint constrains roles of type employee -->
<xtm:association>
<xtm:instanceOf>
<xtm:subjectIndicatorRef
xlink:href="http://www.networkedplanet.com/psi/npcl/constraints/arc-allows-rt"/>
</xtm:instanceOf>
<xtm:member>
<xtm:roleSpec>
<xtm:subjectIndicatorRef
xlink:href="http://www.networkedplanet.com/psi/npcl/constraints/arc-allows-rt-source"/>
</xtm:roleSpec>
<xtm:topicRef xlink:href="#employment-employee-constraint"/>
</xtm:member>
<xtm:member>
<xtm:roleSpec>
<xtm:subjectIndicatorRef
xlink:href="http://www.networkedplanet.com/psi/npcl/constraints/arc-allows-rt-target"/>
</xtm:roleSpec>
<xtm:topicRef xlink:href="#employee"/>
</xtm:member>
</xtm:association>
</xtm:topicMap>Table of Contents
All of the functionality of the TMCore implementation of NPCL is contained in a single namespace, NetworkedPlanet.Npcl and the entire implementation is contained in the assembly NetworkedPlanet.Npcl.dll. The HTML Help file for the TMCore API contains a detailed description of every public interface, class and method in this namespace. This chapter deals with the general principals of the API and gives some short code examples of using the API.
The NPCL data model is represented by a collection of interfaces as shown in the table below.
Table 12.1. Interfaces Representing the NPCL Model
| Interface Name | Notes |
|---|---|
| ISchema | Represents an NPCL schema. Contains lists of all of the different types contained in the schema and provides index methods for finding types and constraints by several different criteria. |
| ISchemaItem | The base interface for all types and constraints in a schema. Provides methods for retrieving or modifying the extension values on a schema item. |
| IType | The base interface for all types in a schema. Derived from ISchemaItem, this interface adds support for getting/setting the display name and subject identifiers of a type and for getting/setting the Is Abstract Facet value. |
| IValueType | The base interface for types that support Value Facets. Derived from IType, this interface adds support for getting/setting the Datatype, Minimum Value, Maximum Value and Value Pattern Facets. Currently only the IOccurrenceType interface is dervied from this interface. |
| IAbstractType | Represents an Abstract Type in the schema - a topic that participates in the class hierarchy, but is not one of the concrete meta-types. |
| IAssociationType | Represents an Association Type in the schema. Derived from IType, this interface adds support for getting/creating/removing the Association Role Constraints that apply to the Association Type. |
| IOccurrenceType | Represents an Occurrence Type in the schema. This interface is dervied from the IValueType interface. |
| IRoleType | Represents a Role Type in the schema. This interface is dervied from the IType interface. |
| ITopicType | Represents a Topic Type in the schema. Derived from the IType interface, this interface adds support for getting/creating/removing the Occurence Constraints and Role Player Constraints that apply to the Topic Type. |
| IScopingTopic | Represents a Scoping Topic in the schema. This interface is derived from IType. |
| IConstraint | The base interface for representation of constraints in the schema. This interface is derived from ISchemaItem and adds support for getting/setting the Minimum Cardinality and Maximum Cardinality Facets. |
| IAssociationRoleConstraint | Represents an Association Role Constraint. Derived from IConstraint, this interface adds support for retrieving the Association Type and Role Type that participate in the constraint and for getting/setting the Arc Label Facet for the constraint. |
| IOccurrenceConstraint | Represents an Occurrence Constraint. Derived from IConstraint, this interface adds support for retrieving the Topic Type and Occurrence Type that participate in the constraint. |
| IRolePlayerConstraint | Represents a Role Player Constraint in the schema. This interface is dervied from IConstraint and adds support for retrieving the Association Type, Role Type and Topic Type that participate in the constraint. |
To work with the API it is important to understand the containment hierarchy of the NPCL model - that is, which items in the model are "parents" that contain other items in the model. The containment hierarchy is quite simple and is shown in the UML diagram below - the black diamond indicates the "container" and the undecorated end indicates the "contained" item.
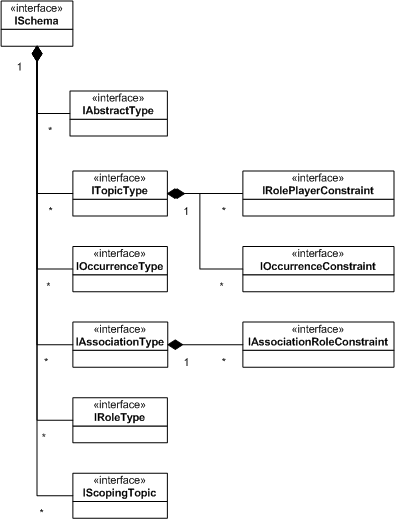
In addition to the interfaces that represent the schema model, the
NetworkedPlanet.Npcl namespace provides classes for loading schema
information from an XML file or from a topic map and for writing schema
information to an XML file or topic map. In addition several convenience
methods are provided in the class
NetworkedPlanet.Npcl.SchemaUtils. These utility
classes are described in more detail in the following chapter on using the
API.
This chapter desribes the principal operations that you can perform through the NPCL API.
The API allows you to create a new schema from scratch. The schema model is built in memory and can then be written to an XML file or into a topic map stored on a TMCore server using the APIs described in the section called “Saving A Schema”.
To create a new schema, use the static method
CreateSchema() in the
SchemaUtils class. This method returns a new
instance of the ISchema interface.
New types and scoping topics can be added to the schema using the
Create... methods of the ISchema interface. Each Create... method
requires two identifier strings. The type ID string is an internal
identifier that will not be used unless the schema is written as an NPCL
XML file, in which case the ID will be written as the
id attribute of the NPCL XML element. The subject
identifier should be a URI identifier for the type. Each unique type
must have a different subject identifier. It is an error to create two
types of the same meta-type with the same subject identifier. However,
it is allowed to create two types of different meta-types with the same
subject identifier.
Constraints can be added by using the Create...() method on the parent type for the constraint (as shown in the containment hierarchy diagram in the previous section). So, to create an Association Role Constraint, use the CreateAssociationRoleConstraint() method on the IAssociationType instance that the constraint applies to. The Create... methods for constraints require you to specify the other types that participate in the constraint and the value of the Minimum and Maximum Cardinality constraints.
The code below shows a simple example of creating a schema from scratch using the API.
Example 12.1. C# Code To Create An NPCL Schema
// Every type will use the same base URI for its subject identifier
string psiBase = "http://www.networkedplanet.com/npcl/tests/";
// Get a new blank schema
ISchema schema = SchemaUtils.CreateSchema();
// Person Topic Type
ITopicType person = schema.CreateTopicType("person", psiBase + "person");
person.DisplayName = "Person";
// Company Topic Type
ITopicType company = schema.CreateTopicType("company", psiBase + "company");
company.DisplayName = "Company";
// Employment Association Type
IAssociationType employment = schema.CreateAssociationType("employment", psiBase + "employment");
employment.DisplayName = "Employment";
// Employer Role Type
IRoleType employer = schema.CreateRoleType("employer", psiBase + "employer");
employer.DisplayName = "Employer";
// Employee Role Type
IRoleType employee = schema.CreateRoleType("employee", psiBase + "employee");
employee.DisplayName = "Employee";
// Employment association allows exactly 1 Employer role
employment.CreateAssociationRoleConstraint(employer, 1, 1, "Employs");
// Employment association allows exactly 1 Employee role
employment.CreateAssociationRoleConstraint(employee, 1, 1, "Works For");
// A Person can play the role of Employee 0 or more times
person.CreateRolePlayerConstraint(employee, employment, 0, Cardinality.Unbounded);
// A Company can play the role of Employer 0 or more times
company.CreateRolePlayerConstraint(employer, employment, 0, Cardinality.Unbounded);
// Age Occurrence Type allows integer values between 0 and 120
IOccurrenceType age = schema.CreateOccurrenceType("age", psiBase + "age");
age.DatatypeConstraint = "http://www.w3.org/2001/XMLSchema#int";
age.MinValueConstraint = "0";
age.MaxValueConstraint = "120";
// Person Topic Type can have 0 or 1 Age occurrences
person.CreateOccurrenceConstraint(age, 0, 1);
// Language Topic Type
ITopicType languageTt = schema.CreateTopicType("language", psiBase + "language");
languageTt.DisplayName = "Language";
// Language topics can be used to scope Names or Occurrences (but not Associations)
languageTt.ScopingFacet = Scoping.Name | Scoping.Occurrence;
// Secret Scoping Topic
IScopingTopic secret = schema.CreateScopingTopic("secret", psiBase + "secret");
// Entity Abstract Type
IAbstractType entity = schema.CreateAbstractType("entity", psiBase + "entity");
// Legal Entity Abstract TYpe
IAbstractType legalEntity = schema.CreateAbstractType("legal-entity", psiBase + "legal-entity");
// Create A Class Hierarchy with Entity as the root.
entity.AddDirectSubclass(legalEntity);
legalEntity.AddDirectSubclass(person);
legalEntity.AddDirectSubclass(company);
The NPCL API provides a small number of functions for retrieving
type and constraint information from a schema. The key methods are all
found on the ISchema interface. This
interface provides properties TopicTypes,
OccurrenceTypes,
AssociationTypes, RoleTypes
and ScopingTopics that return the types and scoping
topics in the schema. This interface also provides methods named
GetTopicType(),
GetOccurrenceType() etc. that return the type
with the specified subject identifier. The method
GetSchemaTypes() returns all types with the
specified subject identifier (as one subject identifier can be used on
several different types).
Finally the ISchema interface
provides three additional lookup methods. The method
GetPlayerTypesForRole(IRoleType,
IAssociationType) returns all
ITopicType instances that are allowed to
play the specified type of role in the specified type of association.
The method
GetPlayerConstraintsForRole(IRoleType) returns
all IRolePlayerConstraint instances that
reference the specified IRoleType. The
method GetAssociationTypesForRole(IRoleType)
returns all IAssociationTypes that allow a role of the specified type to
appear.
The NPCL API provides two classes for saving a schema. To save a schema to an NPCL XML file, use the class NetworkedPlanet.Npcl.XmlSchemaWriter. To write a schema to a topic map stored in a TMCore server, you can use the class NetworkedPlanet.Npcl.TopicMapSchemaWriter.
The XmlSchemaWriter is simply initialised with the XmlWriter that the output is to be written to. Some control over how the schema is written is provided by the properties NpclPrefix which sets the prefix to be used for the NPCL XML Namspace; and WriteAsFragment which controls whether the schema is written as a full XML document or as a fragment (with no XML declaration).
Example 12.2. Writing a Schema as XML
FileInfo outputFile = new FileInfo("myschema.xml");
Stream output = outputFile.Open(FileMode.Create, FileAccess.Write);
XmlTextWriter xmlWriter = new XmlTextWriter(output, System.Text.Encoding.UTF8);
xmlWriter.Formatting = Formatting.Indented;
// Create a new XmlSchemaWriter to write as a full XML document
// using the prefix "npcl" for the NPCL XML Namespace.
XmlSchemaWriter schemaWriter = new XmlSchemaWriter(xmlWriter, false, "npcl");
schemaWriter.WriteSchema(originalSchema);
// NOTE: The XmlSchemaWriter does not close the XmlWriter at the end of the document.
xmlWriter.Close();The TopicMapSchemaWriter class writes the
schema information into an ITopicMap
instance, storing the schema information in the TMCore database as
topics and associations in the topic map. The
TopicMapSchemaWriter can operate in one of three
different modes.
- ReplaceAll
In this mode all existing schema information in the topic map is removed and replaced by the schema being written.
- ReplaceExisting
In this mode existing type and constraint information in the topic map is overwritten by the input schema, but types and constraints not specified in the input schema are left in the topic map.
- UpdateExisting
In this mode existing types and constraints are updated, adding any new information contained in the input schema without removing existing constraints contained in the topic map.
The NPCL API provides two classes for loading a schema into memory. To load a schema from an NPCL XML File, use the class NetworkedPlanet.Npcl.XmlSchemaReader. To load a schema from a TMCore topic map, use the class NetworkedPlanet.Npcl.TopicMapSchemaReader. Both of these classes conform to the common interface ISchemaReader.
The ISchemaReader interface defines a boolean property, Strict. If this property is set to true, then the first error encountered in reading schema information will result in an NpclException (or one of its derived classes) being thrown. If this property is set to false, the reader will attempt to recover from any errors it encounters. If Strict is set to false, then after processing, the Errors property of the ISchema interface lists all of the NpclExceptions that were caught and recovered from during processing.
Example 12.4. Reading A Schema
ISchemaReader schemaReader = new XmlSchemaReader( new FileStream("simple-ontology.npcl", FileMode.Open) );
// or with an ITopicMap object called myTopicMap:
// ISchemaReader schemaReader = new XmlSchemaReader( myTopicMap );
schemaReader.Strict = false;
ISchema schema = schemaReader.ReadSchema();
foreach(NpclException error in schema.Errors) {
System.Console.WriteLine(error.Message);
}In addition to providing classes to parse from and write to topic
maps, the NPCL API also provides an implementation of the
ISchema interface that is directly
connected to the database. All type, constraint and property retrievals
are implemented as database queries and all modifications made to types
or constraints are committed to the database when they are made. The
class that provides this implementation is the class
NetworkedPlanet.Npcl.TopicMapSchema. The class is
created by passing in the ITopicMap
instance that it will work against as the single constructor parameter.
This class implements the ISchema
interface and can be used in the same way as an ISchema instance
returned by the TopicMapSchemaReader or
XmlSchemaReader classes.
Note
This implementation is designed for developers who want to
create their own GUI tools for manipulating schemas stored in a TMCore
database. You should NOT use this implementation for most applications
- the TopicMapSchemaReader is optimised to read
a schema from a database into memory in large batches and is usually
more efficient than the TopicMapSchema
implementation for applications that need to lookup schema information
and/or traverse the schema.
The NPCL API provides a basic schema inference engine, that can examine a topic map to determine what types exist and how they are used. The programming interface to this engine is the method InferSchema(ITopicMap, string) in the class NetworkedPlanet.Npcl.SchemaUtils. To use this method you must pass in the ITopicMap handle to the topic map you want to evaluate, and the base URI to be used for generated subject identifiers. The base URI string you pass in can be null, in which case the base URI defaults to the special prefix 'urn:x-tmcore:topicid'.
The inference proceeds by querying the topic map to determine what topics are being used as types; which types of occurrences occur on which types of topics; which types of association roles appear in which types of associations; and which types of topics play which types of association role. The inference also attempts to determine what types of topics are being used in scopes and will read and reflect the superclass-subclass hierarchy if you have used the XTM-defined subject identifiers for the superclass-subclass association type and related role types.
The inference has a number of limitations and failsafes that you should be aware of:
If a topic is found that is used as a type, NPCL requires that the topic must have a subject identifier. If the topic does not already have at least one subject identifier, one will be generated for it. This generated subject identifier will be base URI prefix specified in the method parameters followed by the name of the topic forced into lower case. So if you specify the base URI prefix as 'http://www.mycompany.com/psi/general/', then the topic with the name "Sales Forecast" will get the generated subject identifier 'http://www.mycompany.com/psi/general/sales forecast'.
If you pass in NULL as the base URI prefix, then topics will be assigned a URI of the form 'urn:x-tmcore:topicid:' followed by the database object identifier of the topic. This special form of URI is recognised by the NPCL TopicMapSchemaWriter class, which will find the topic to be updated using its object identifier rather than a subject indicator. This feature is provided to allow you to generate an NPCL schema from a topic map and then import the schema into that topic map without creatin duplicates of topics that did not originally have subject identifiers. You should NOT use this feature to create an NPCL schema that you then intend to import into a different topic map.
Cardinality constraints are generated to be rather lax. Occurrence and role player constraints are generated as either '0 or more' or '1 or more' constraints. A '1 or more' constriant is generated only if every topic of the given type would conform to that constraint. Association role constraints minimum cardinality is generated as 0 or 1 (only if all associations of the given type have at least one role that conforms), and maximum cardinality is generated as either unbounded or 1 (only if all associations of the given type have no more than one role that conforms). You may wish to review the generated constraints and make them tighter in certain applications.
The inference process makes no attempt to infer datatype, minimum value, maximum value or value pattern facets for occurrence types. You should add these manually if they are required.
When a topic is used in a scope, the inference engine works as follows:
If the scoping topic is also a role type and the scoped item is a topic name, the topic is ignored (role types are often used to scope association type names to provide context-sensitive association labels - these are one-off usages and would make the NPCL schema grow unmanageably if they were all recorded).
If the scoping topic is typed, then the appropriate scoping facet value is added to the topic type. So if a topic "English" is used to scope a topic name, and the "English" topic has the type "Language", then the scoping facet value for the type "Language" will include NAME as one of its values.
If the scoping topic is untyped, then a new Scoping Topic is generated in the schema to represent it. Note, that this only occurs if the scoping topic is not typed.
Example 12.5. Generating An NPCL Schema File From A Topic Map
The following code snippet shows how the schema inference engine can be used to generate an NPCL file for use in other topic maps
// Assume that tmSystem is an ITopicMapSystem object that is already initialized
// Get the topic map to process
ITopicMap tm = tmSystem.GetTopicMap("my-topicmap");
// Invoke the SchemaUtils to generate the schema
ISchema schema = SchemaUtils.InferSchema(tm, "http://www.mycompany.com/psi/");
// Write the schema to a file
XmlTextWriter xmlWriter = new XmlTextWriter("my-topicmap.npcl", System.Text.Encoding.UTF8);
xmlWriter.Formatting = Formatting.Indented;
XmlSchemaWriter writer = new XmlSchemaWriter(xmlWriter, false, "npcl");
writer.WriteSchema(schema);
xmlWriter.Close();
Example 12.6. Generating And Adding Schema Information To A Topic Map
The following code snippet shows how the inference engine can be used to populate a topic map with a schema generated from it.
// Assume that tmSystem is an ITopicMapSystem object that is already initialized
// Get the topic map to process
ITopicMap tm = tmSystem.GetTopicMap("my-topicmap");
// Invoke the SchemaUtils to generate the schema
// Using null for the subject identifier base generates identifiers
// that will correctly update topics that do not currently have subject identifiers.
ISchema schema = SchemaUtils.InferSchema(tm, null);
// Write the schema back to the topic map - replacing any previous schema information
TopicMapSchemaWriter writer = new TopicMapSchemaWriter(tm, SchemaWriterMode.ReplaceAll);
writer.WriteSchema(schema);Three samples can be found in the examples
directory of your TMCore installation. These examples show some of the
basic operations that are described above.
Table 12.2. NPCL API Examples
| Example Directory | Concepts Demonstrated |
|---|---|
| examples/CS/Npcl/CreateSchema | Programatically creating an NPCL Schema Model. Writing an NPCL Schema Model out as an NPCL XML file. |
| examples/CS/Npcl/SchemaImporter | Reading an NPCL Schema Model from an NPCL XML file. Updating schema information in a topic map using an NPCL Schema Model. |
| examples/CS/Npcl/SchemaInfo | Reading an NPCL Schema Model from an NPCL XML file. Accessing information from an NPCL Schema Model programatically. |
Note
All of these examples are written in C#. Currently there are no Visual Basic equivalent of these examples.
To compile and run an example, open Visual Studio.NET and create a new blank solution; then add the .csproj contained in the example directory for the example to the solution. The project can then be built using the Build > Build Solution menu item. If the solution contains multiple projects, set the new example project to be the start-up project by right clicking the project in the Solution Explorer pane and selecting "Set as StartUp Project" from the pop-up menu.
Warning
The SchemaImporter example requires a connection to a TMCore database. The connection string for this is specified in the App.config file contained in the example directory. You must ensure that this file has the correct connection string before attempting to run the example.
This example shows how a new NPCL Schema model can be created and populated from scratch. This example creates a simple ontology consisting of the topic types "Person" and "Company" which are both subclasses of "Legal Entity". A Person can have an Age occurrence and can play the role "Employee" in an Employment association. Any topic of type "Legal Entity" can play the role of "Employer" in an Employment association, but this topic type is specified as abstract, meaning that end-users would only be allowed to create topics typed by one of its subclasses (Person or Company).
The example also shows how a schema model can be written out as an NPCL XML file.
The example runs as a console application and takes a single optional parameter. The parameter specifies the name of the XML file that the NPCL schema is to be written to. If the file already exists, it will be overwritten. If the parameter is not specified, the NPCL schema will be written out to the console.
This example shows how an NPCL Schema model can be read in from
one storage format (in this case from an NPCL XML file) and written
out to a different storage format (a topic map in the TMCore
database). A sample schema file is provided in the example directory
(the file simple-ontology.npcl).
The example runs as a console application and takes a two required parameters. The first parameter specifies the name of the XML file that the NPCL schema model is to be imported from. The second parameter specifies the name of the topic map that the schema information is to be written to. If the named topic map does not already exist in the database, it will be created. If the topic map does already exist, the schema information will be used added to the topic map, overwriting any existing schema information for the same types (any other types in the topic map will be unaffected).
This example shows how to access an NPCL Schema Model from your code. In this case the schema information is read from an NPCL XML file.
The example runs as a console application and takes a single required parameter. The parameter specifies the name of the XML file that the NPCL schema model is to be imported from. When the application runs it first displays a count of the different types contained in the schema. You are then prompted to choose if you wish to see detailed information. The detailed information lists details on each topic type and association type in the schema and finally displays a complete class hierarchy for the schema showing all types and their subtypes.
Table of Contents
When programming code or the TMWS web services are used to update a topic map, repeated updates can lead to the possibility of duplicate information being recorded in a topic map. TMCore provides two database stored procedures that clean up this duplicate information, reducing database size and improving topic map consistency.
This chapter describes what "duplicate information" means in the context of a topic map and goes on to describe the stored procedures that can be used to remove duplicate information.
Duplicate information in a topic map falls into one of three categories: duplicate information on a topic; duplicate information on an association; and duplicate associations.
Duplicate information on a topic is found when an topic identifier, name, variant name or occurrence repeats exactly the same information as another item of the same type on the same topic. A duplicate name is one that has the same string value and scope as another name on the same topic. A duplicate variant name is one that has the same string value, scope and parent name as another variant on the same topic. A duplciate occurrence is one with the same string value, type and scope as another occurrence on the same topic. A duplicate identifier is a source locator, subject identifier or subject locator that has the same value as another identifier of the same type on the same topic.
How these duplicates are managed varies depending on the type of duplicate information.
Duplicate names are managed by moving all variant names and source locators from the duplicate name to the name that it duplicates and then removing the duplicate name.
Duplicate variant names are managed by moving all source locators from the duplicate variant name to the variant name that it duplicates and then removing the duplicate variant name.
Duplicate occurrences are managed by moving all source locators from the duplicate occurrence to the occurrence that it duplicates and then removing the duplicate occurrence.
Duplicate identifiers are managed by simply removing the duplicate identifier.
With an association, duplicate information is found when a source locator of the association has the same value as another source locator on the same association, or when a role in the association has exactly the same role player and role type as another role on the same association.
Duplicate source locators are managed by remvoving the duplicate.
Duplicate association roles are managed by moving all source locators from the duplicate association role to the role that it duplicates and then removing the duplicate association role.
Two associations are consider to be duplicates if they are both in the same topic map, have the same type, scope and number of role players and if for each role in one of the associations, there is a role in the other association with the same role type and role player.
Duplicate associations are managed by moving all source locators from the duplicate association to the association that it duplicates and then removing the duplicate association.
Two stored procedures are provided by TMCore to implement the duplicate removal policies described above. These stored procedures can be invoked by any member of the tm_writer database role.
tm_RemoveDuplicates. This stored procedure is invoked with no parameters and removes all duplicate information from all topic maps in the database.
tm_RemoveDuplicatesFromTopicMap. This stored procedure takes a topic map OID as its only parameter and removes all duplicate information from the topic map identified by that parameter.
Either of these duplicate removal stored procedures can be invoked either using TSQL in a command-line application such as the SQL Server ISQL.EXE application, or using the appropriate database management tool such as SQL Server Management Studio for SQL Server 2005. The stored procedures can also be invoked directly through code using the TMCore APIs. The following is an example of how to invoke the tm_RemoveDuplicates procedure from code:
// Assume the tms variable holds an ITopicMapSystem instance
// Invoking the stored procedure with a command-timeout value of
// 0 allows for a potentially long-running procedure call.
tms.ExecuteQuery("EXEC tm_RemoveDuplicates", 0);
Similar code can be used to invoke tm_RemoveDuplicatesFromTopicMap to target a specific topic map:
private void RunTopicMapDuplicateSuppression(ITopicMap tm)
{
Hashtable parameters = new Hashtable();
parameters["@tmId"] = tm.ID;
tm.TopicMapSystem.ExecuteQuery(
"EXEC tm_RemoveDuplicatesFromTopicMap @tmId",
parameters, 0);
}
The TMCore assembly makes use of the Apache Log4Net logging library to provide configurable runtime logging services. Log4Net provides a flexible hierarchical logging system that supports a wide variety of logging formats and logging destinations include files, console and the system event log. Details on how to Log4Net's features and how to configure the Log4Net system can be found on the Apache Log4Net site at http://logging.apache.org/log4net/.
The TMCore assemly does not itself initialise the Log4Net library which allows developers creating applications that use TMCore to choose their own method of configurable or hardcoded logging configuration.
Note
The Topic Map Web Service and NPCL Web Service web applications do provide a default, overrideable configuration for the Log4Net system - see the documentation for those applications for more details.
Log4Net supports the concept of a hierarchical set of logs, so for example the log "networkedplanet.tmcore" is a child of the log "networkedplanet". Configuration that applies to the parent log also applies to the child log unless overridden. This is covered in much more detail in the Apache documentation for Log4Net. The TMCore assembly writes to the following logs:
- networkedplanet.tmcore.system
This log receives the following types of messages:
ERROR messages when a topic map processing exception occurs such as an attempt to add a duplicate source locator.
ERROR messages if the system cannot execute a set of SQL statements against the database for some reason.
INFO messages when the TMCore
ITopicMapSystemis initialised and closed.DEBUG messages when a query is executed through the
ITopicMapSystem.ExecuteQuery()method.DEBUG messages detailing the configuration parameters passed when the TopicMapSystem is initialised
Warning
If you are using database authentication with a password specified in the connection string, these DEBUG messages will contain the user name and password used for the connection in clear text. You should either disable DEBUG level logging or ensure that logs containing this sensitive data are not accessible to unauthorized users.
- networkedplanet.tmcore.merging
This log only receives DEBUG messages when the system detects and performs a merge of two topics.
- networkedplanet.tmcore.syntax.xtm
Receives INFO and DEBUG level messages as an XTM source is parsed into the topic map. The INFO level messages can be used for timing imports. The DEBUG level messages are quite verbose and not recommended except for debugging purposes.
- networkedplanet.tmcore.util.hierarchy
This log receives the following types of messages:
ERROR messages if a required PSI has not been defined in the topic map.
WARNING messages if a facet is found which cannot be processed as a hierarchy for some reason.
DEBUG messages as a
HierarchyManagerinstance loads or refreshes topic hierarchy data.