Open Data Camp 2
After missing out on ODCamp1 which was held in Winchester earlier in the year, I was looking forward to seeing what was in store for those attending the second. A storify summary of ODCamp1 had me excited for the content of the sessions that would be held, all with some kind of focus on Open Data, this time based in Manchester.
ODCamp is an unconference - the venue, organisation and promotion are handled by the ODCamp team, and then the sessions are decided at the beginning of each day by any attendee lining up to quickly pitch what their session could entail. After each pitch a show of hands helps the organisers decide on what kind of space would be needed for the session - and very quickly the schedule is arranged for the day.

Instantly I had a problem - I wanted to go to all of them! But short of waiting til nobody was looking and rearranging the post-it notes (an idea I quickly abandoned as too risky to escape unnoticed), I had to make some tough choices.
Instead of attempting to summarise every session I went to (tempting, but this post would expand into thousands of words) just write about a few of my personal highlights (spoiler: I thought it was FANTASTIC) and urge you to stay up to date with the ODCamp team for news about future events.
Something for everyone
Attendees came from all kinds of different backgrounds, techies and non-techies alike. The one commonality was a shared interest in publishing data. The differences were a key element that made the camp work so well - each discussion would represent a fairly wide range of views and requirement needs, meaning that no matter what your own interest, you always walked away with food for thought.
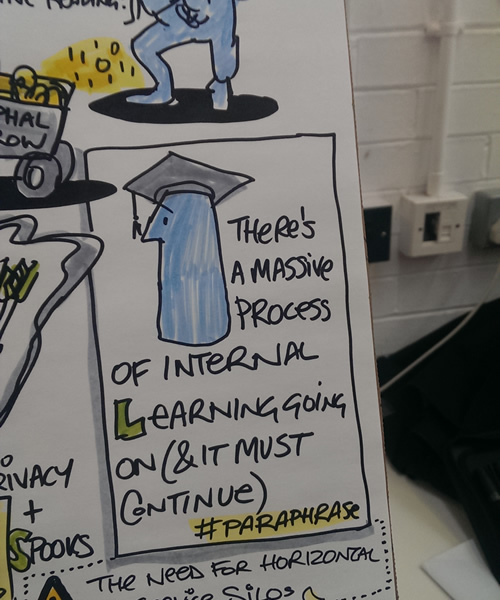
Drawnalism
Matt from Drawnalism was live recording sessions as large illustrations which were not only incredibly impressive to see happening and check out after a session, but I also knew just how valuable they would be after the event. It was seeing the illustrations from the last ODCamp that gave me such a clear idea of exactly what went on during the sessions, and after seeing them I’d instantly registered to not miss out on the next event. I know that sounds like a massive plug, but so be it, you cannot help but be impressed after turning around after an hour’s worth of lecture and/or dicussion to find the most salient points distilled and and then presented in a glorious hand illustrated info-graphic. Respect.



Making Open Data Suck Less
With a provocative title for a pitch, Chris Gutteridge led a session towards the end of day one aimed at trying to improve the quality of Open Data. There were quite a few laughs to be had whilst people threw in their pet hates, and then very interesting discussions about what we could do to help alleviate them. Common problems were the publishing of “open” data in custom file formats, having to get through download forms to get to the data and bad data itself (e.g. a column of measurements that change whether it was recorded in mm or inches, sometimes using only numerals). As the session wrapped up it was great to hear solutions being thrashed out - such as suggestions for content of documentation (giving a better description of the data itself and links to learn more about it, what format is the data in? does it require a special program? is there a free version of the program if so?). Another good suggestion was a central wiki-style encyclopedia, an idea tempered by the need for that to be managed and someone’s responsibility. However, Amanda from the ODI did mention that it was an idea that kept coming up and so I look forward to hearing more from them about it.
Unkeynotes
Completely unplanned, there were two pitches that had such interest from everyone attending that the organisers helpfully did not place anyone else’s pitches at the same time. On day one it was bums on seats for a talk from Paul Maltby, Director of Data from the Cabinet Office. He gave an impassioned overview of the plans he and his team have to improve the way data is handled within the Cabinet Office. It will be interesting to keep track of the progress they make over the next year or so and whether the good intentions turn into published datasets.
John Murray’s session on spatial analysis queries led into a interesting discussions on personal perception of “place”, and on to who really “owns” addresses. As time ran out, this prompted a pitch for more on the debate - turning into day two’s unkeynote from Bob Barr with the full rundown “Address Wars” history. I can’t possibly summarise it all here, but we can only hope that Open Addresses gets another boost to continue the amazing work they started.
It’s important to demystify RDF
For an event targeted specifically at Open Data enthusiasts, I was surprised to find that there were very few that were comfortable with Linked Data. Some were unaware of it entirely, some knew a bit about it but weren’t sure of its benefits, and others were very comfortable with the idea of it but put it to one side as if it was some kind of pipe-dream rather than a simple step onwards from CSV style tabular data. It prompted me to do a pitch myself on the second day, targeted specifically to those people who would like to have a play around with RDF, but weren’t sure how to go about doing that. I ran a quick session to use OpenRefine to convert CSV to RDF using the RDF extension to map columns to predicates, and then we had a bit of a chat around the subjects of re-using existing Linked Data vocabularies (do you have to? no you don’t). Fear not if you’d like me to write more on this subject, I’ve taken notes from the questions asked during that session and will do a separate blog post on that subject.
The weekend-long camp concluded with a feedback session to chat about any points that particularly worked or didn’t work over the weekend. This was in keeping with the unconference ethos - the attendees come together and pitch in to build a conference on the fly. It works fantastically when done well, and hats off to the organisers for making ODCamp one of those. ODCamp3 is looking like it will be held in about six months time - head over to ODCamp website and sign up to get updates.
Also check out:
- Open Data Camp 2 in pictures (via Guiseppe Sollazzo on Flickr)
- The #odcamp hashtag on twitter
- ODCamp website